-
Bug
-
Resolution: Done
-
.
Must be fixed in any of the upcoming builds and should be included in the current release.") High
High
-
Casablanca Release
-
None
-
None
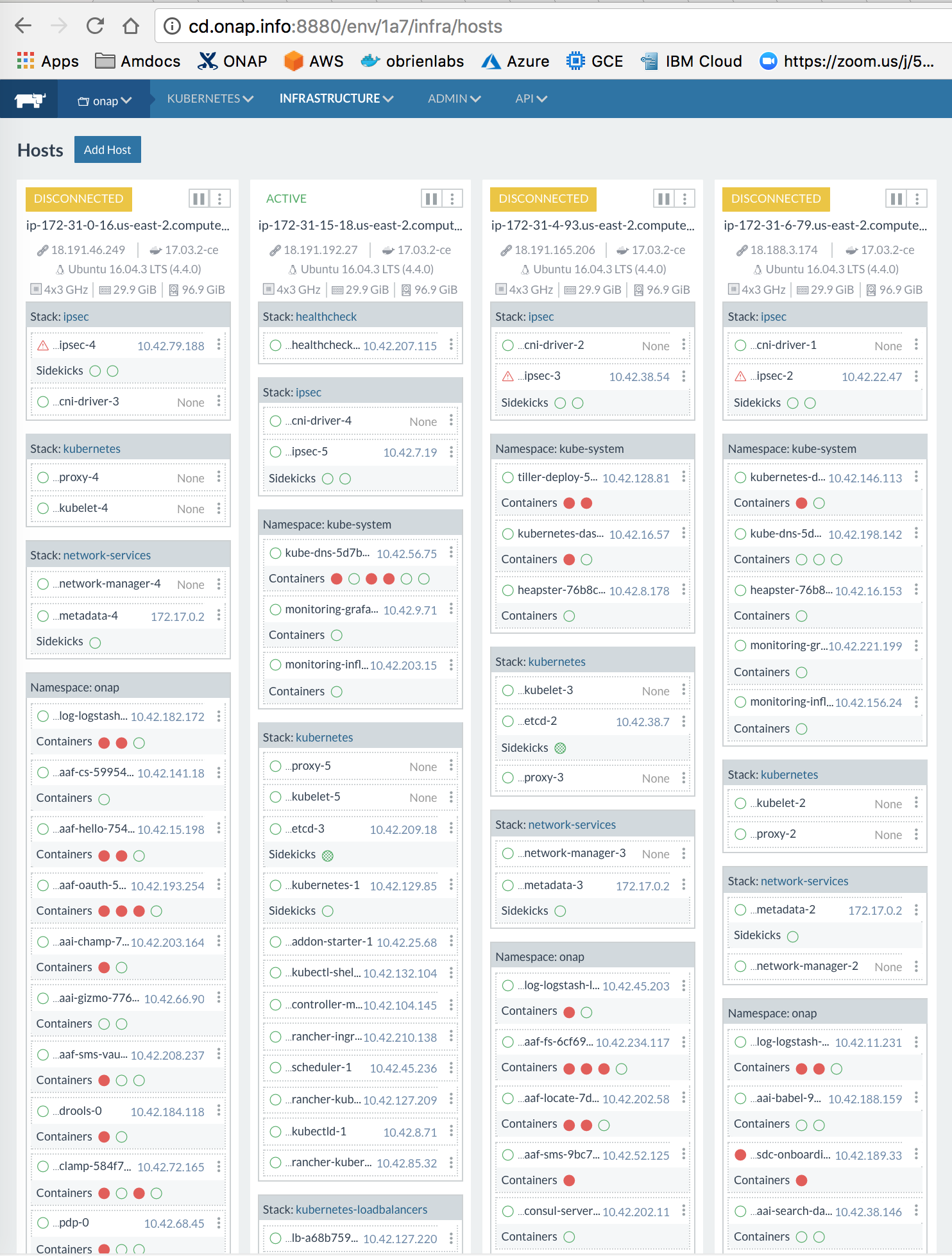
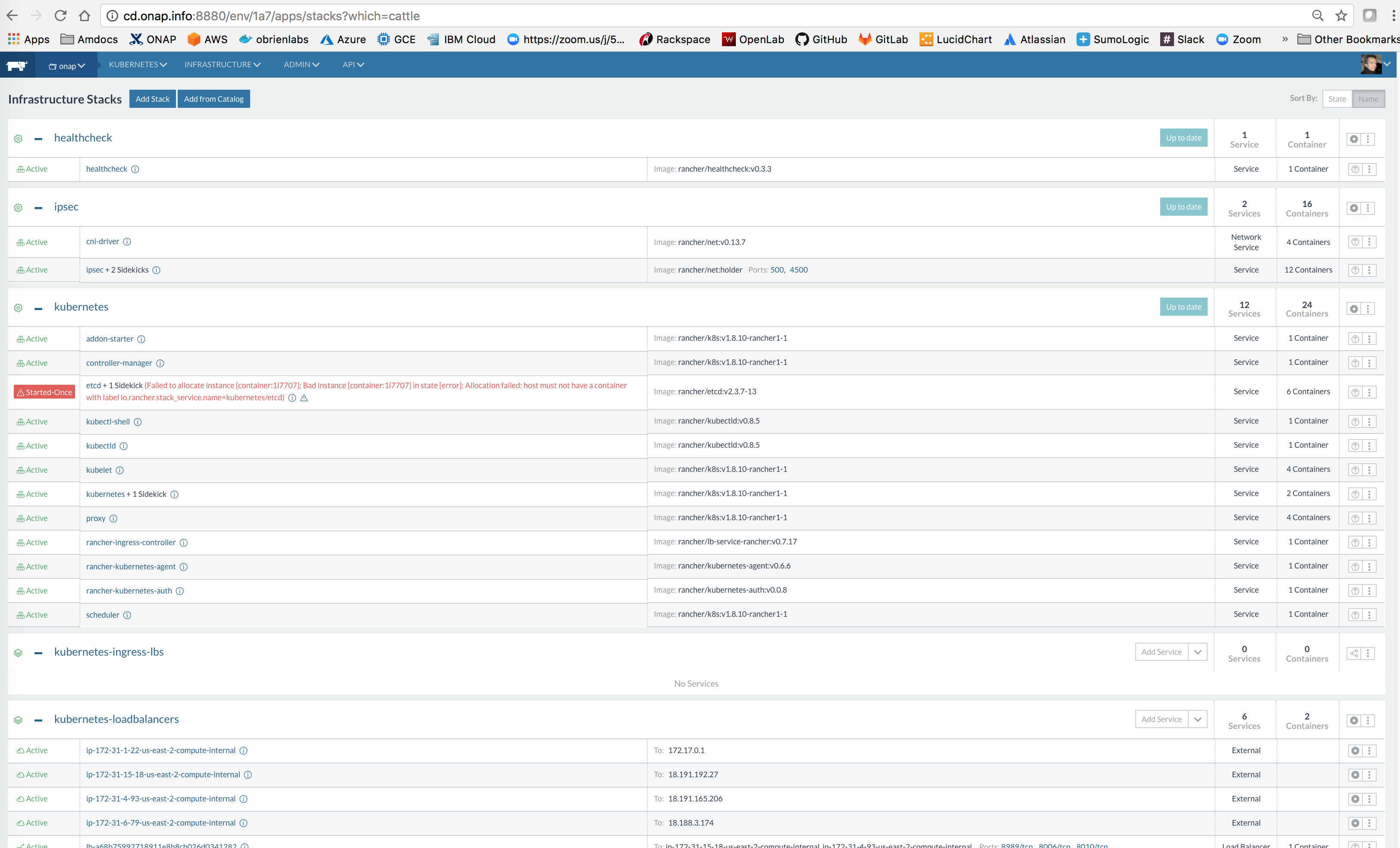
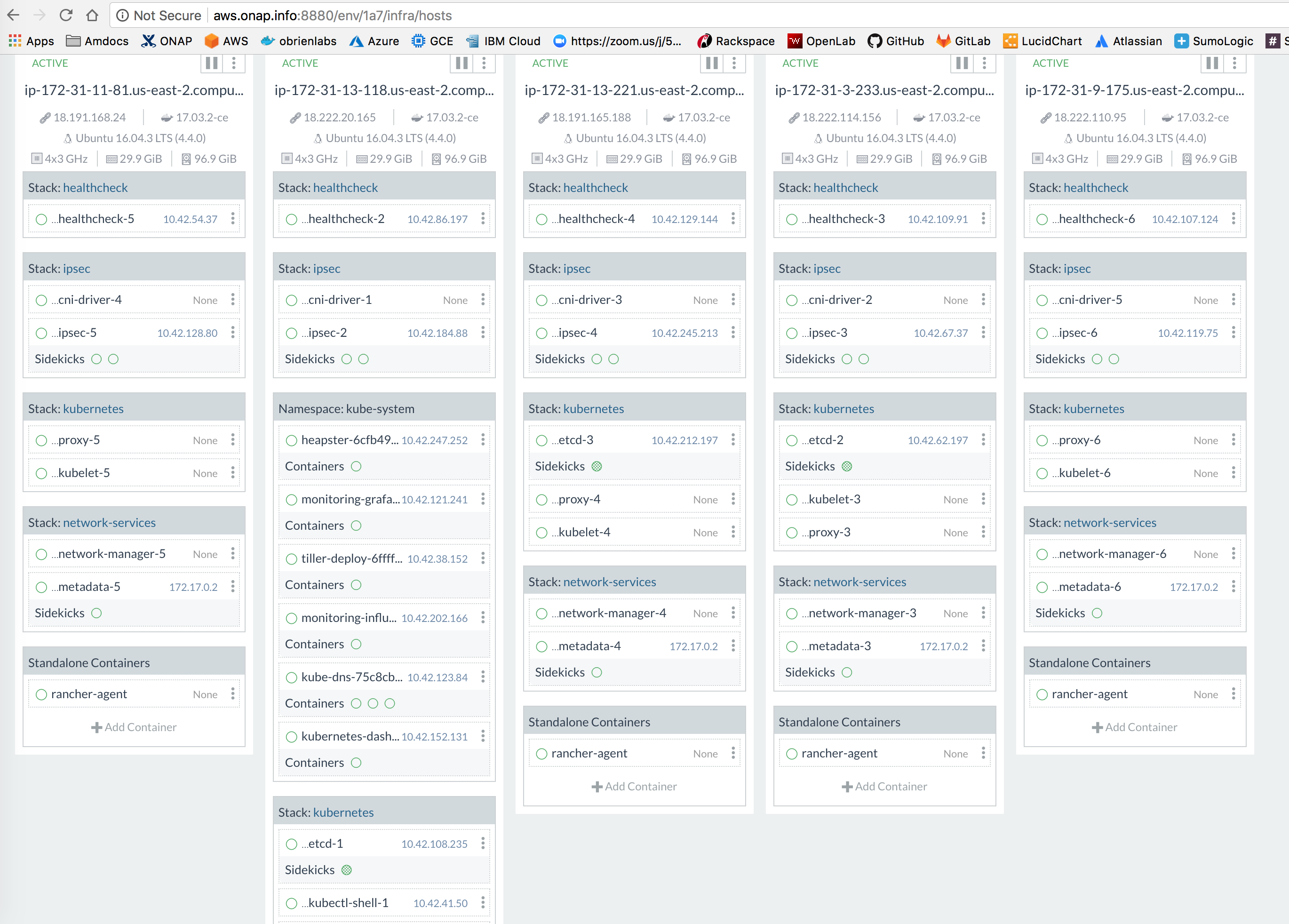
![]() Nothing looks to have changes but a new cluster - for example a 4+1 node AWS cluster starts to degrade in under 24 hours
Nothing looks to have changes but a new cluster - for example a 4+1 node AWS cluster starts to degrade in under 24 hours
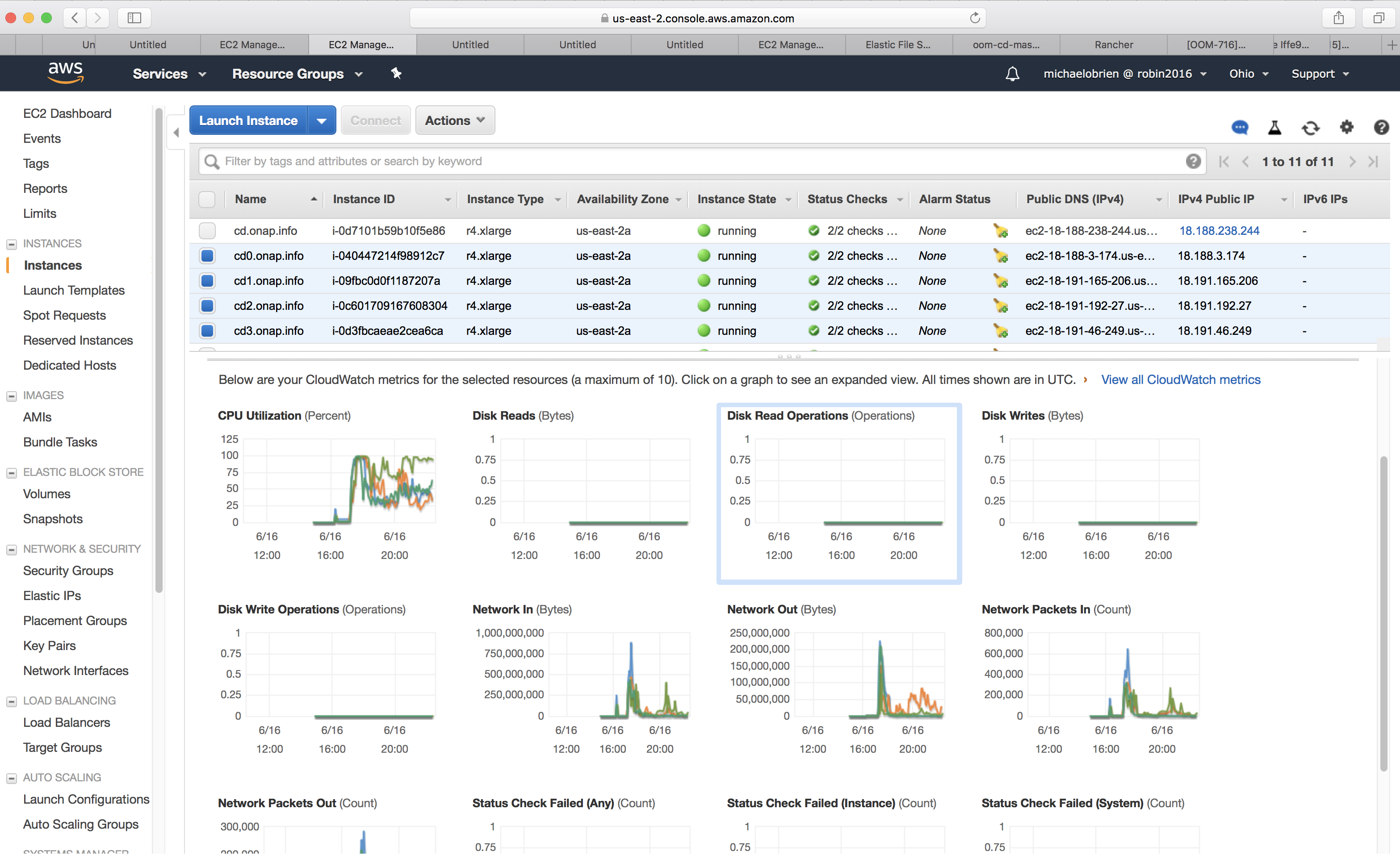
Previous clusters were OK for weeks
The master.onap.info cluster created 18 days ago is OK
check the usual FS, RAM, etcd
could be https://github.com/rancher/rancher/issues/13176
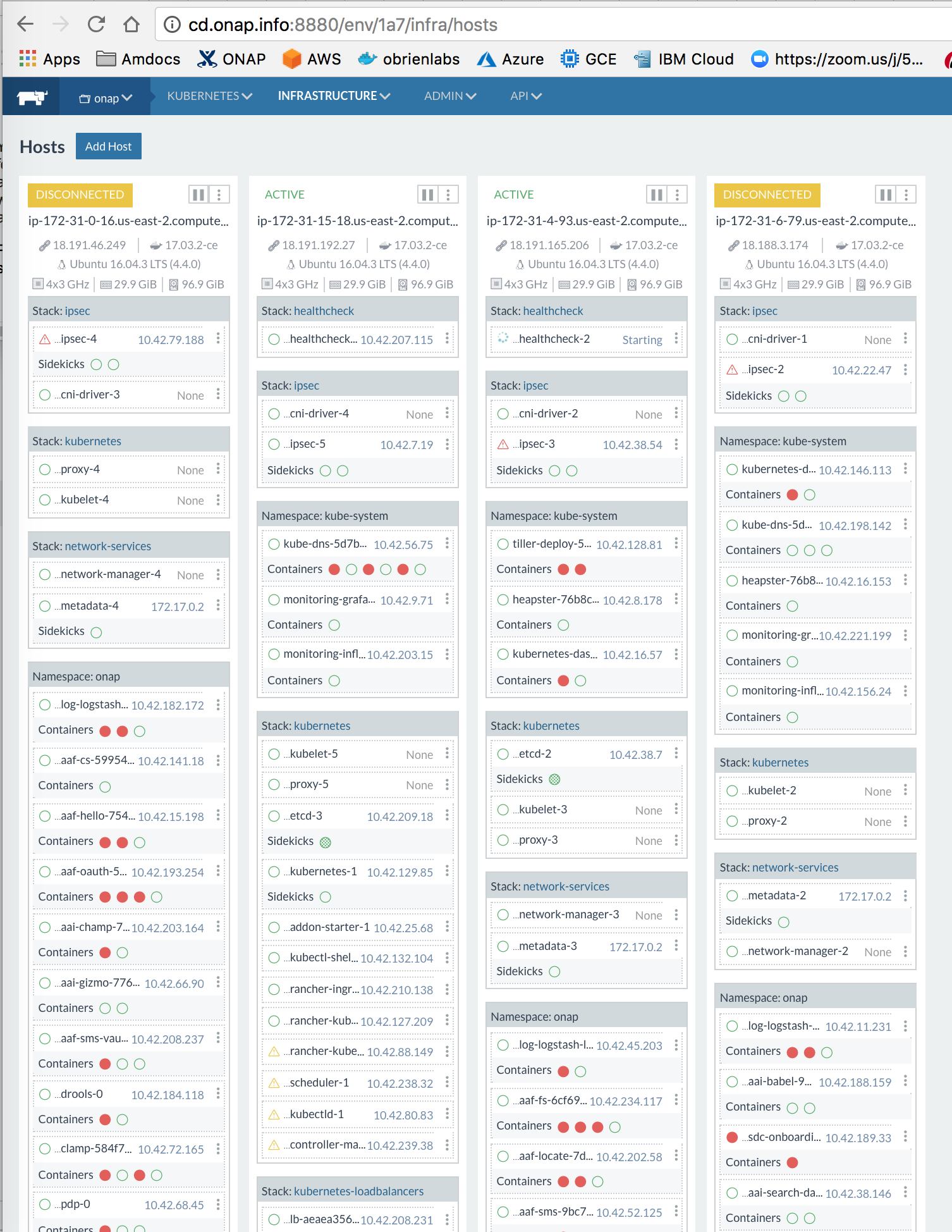
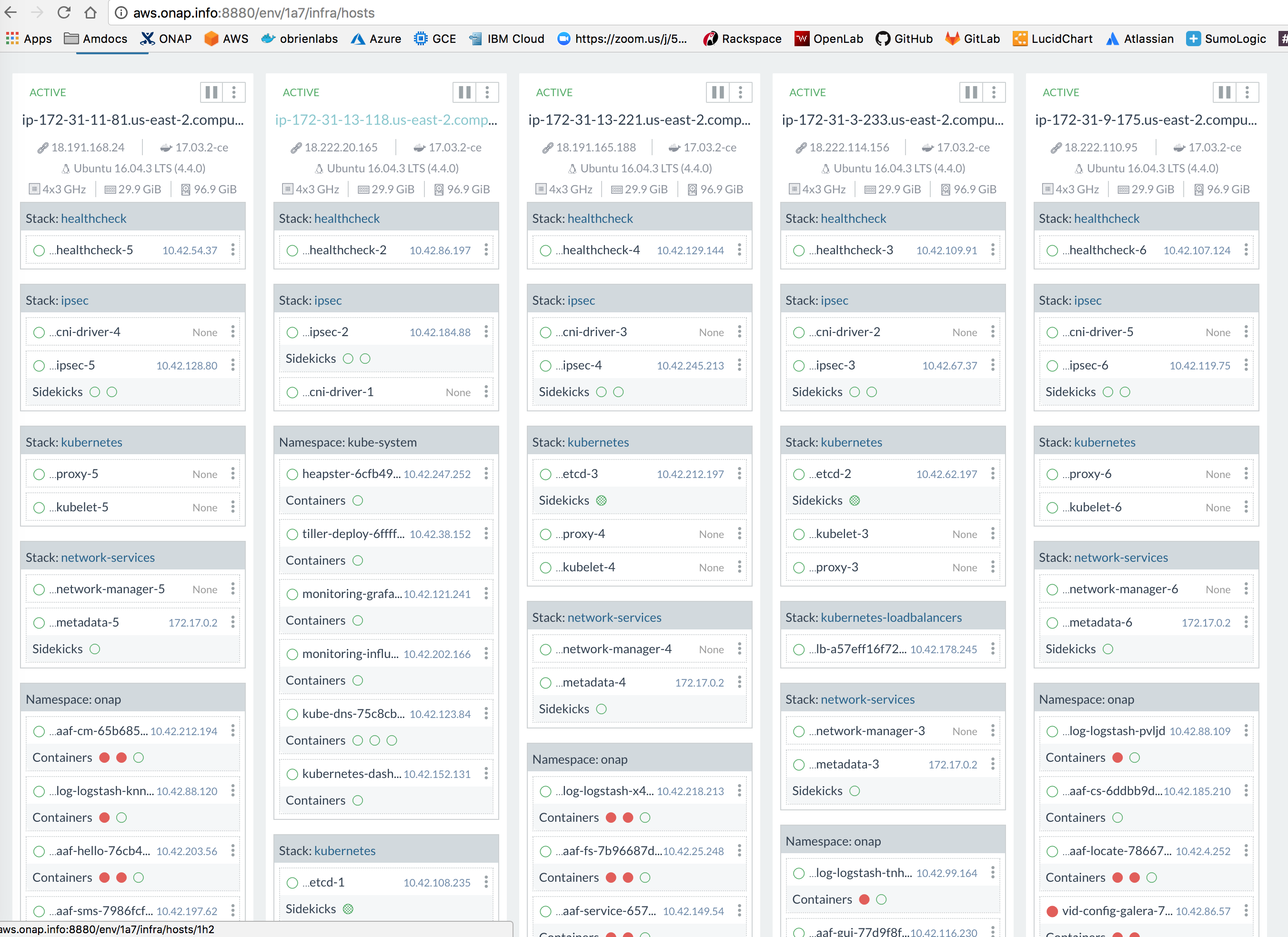
![]() as other tests
as other tests
1) letting a 1.6.18 cluster sit empty for 24 hours to verify the same ipsec issue
2) installing onap on the cluster to see if we see the same detached behaviour