-
 Story
Story
-
Resolution: Done
-
 Medium
Medium
-
None
-
None
-
None
Based on the findings documented in CPS-277 Spike Analyse E2E API GET methods
we discovered we need the following cps path query
- Get the ancestor of the given schema node identifier.
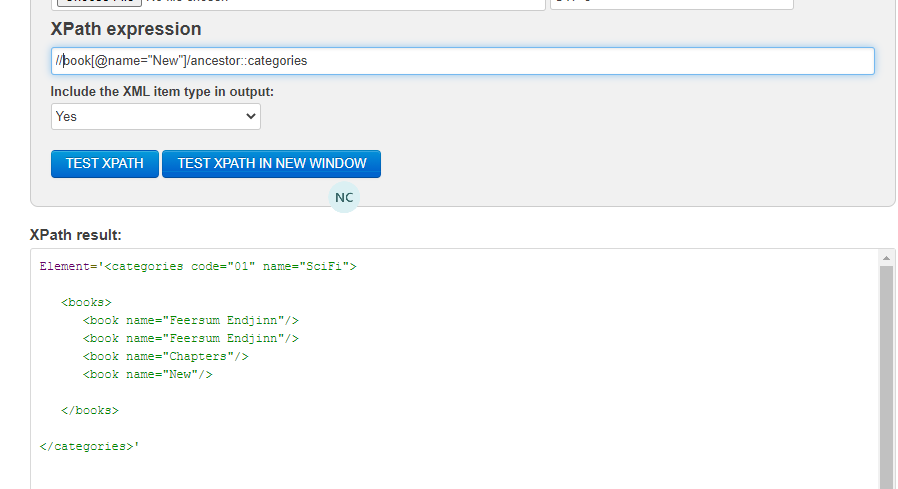
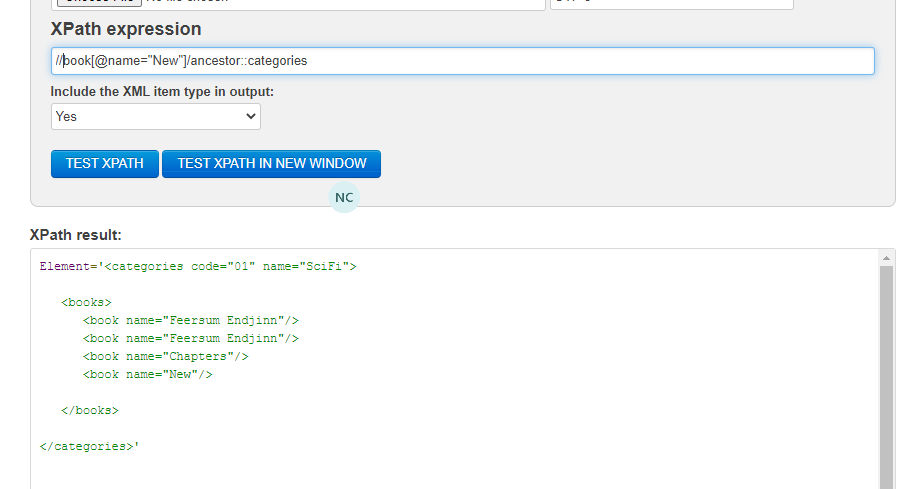
For example, if you insert the following data and xpath expression in https://www.freeformatter.com/xpath-tester.html#ad-output
<bookstore name="Chapters">
<bookstore-name>Chapters</bookstore-name>
<categories code="01" name="SciFi">
<books>
<book name="Feersum Endjinn"/>
<book name="Feersum Endjinn"/>
<book name="Chapters"/>
<book name="New"/>
</books>
</categories>
<categories code="02" name="kids" />
<categories code="03" name="Chapters" >
<books>
<book name="Feersum Endjinn"/>
<book name="Feersum Endjinn"/>
<book name="Chapters"/>
</books>
</categories>
</bookstore>
//book[@name="Chapters"]/ancestor::bookstore
This will find the child book with the name Chapters and then find its ancestor of type bookstore.
We need to be to apply this logic to cps by using the cps path query.
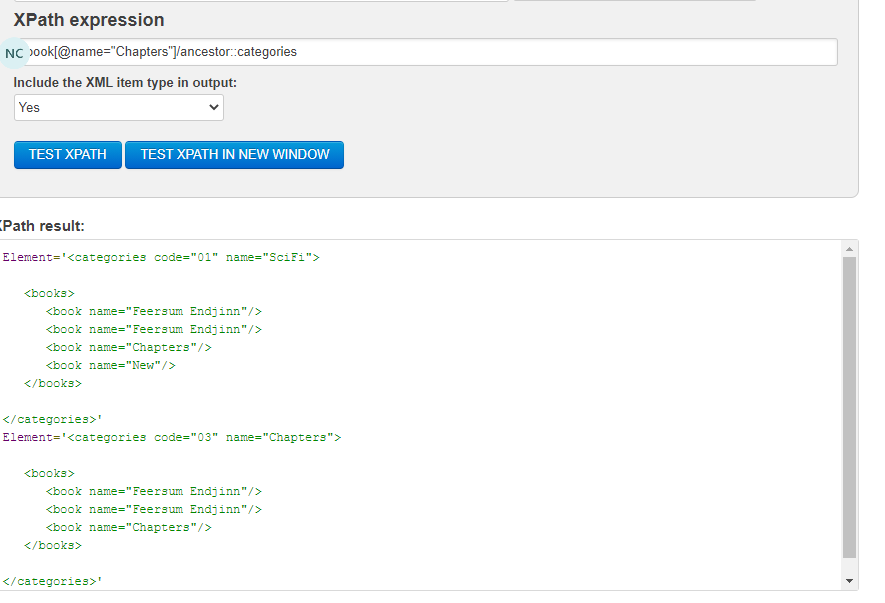
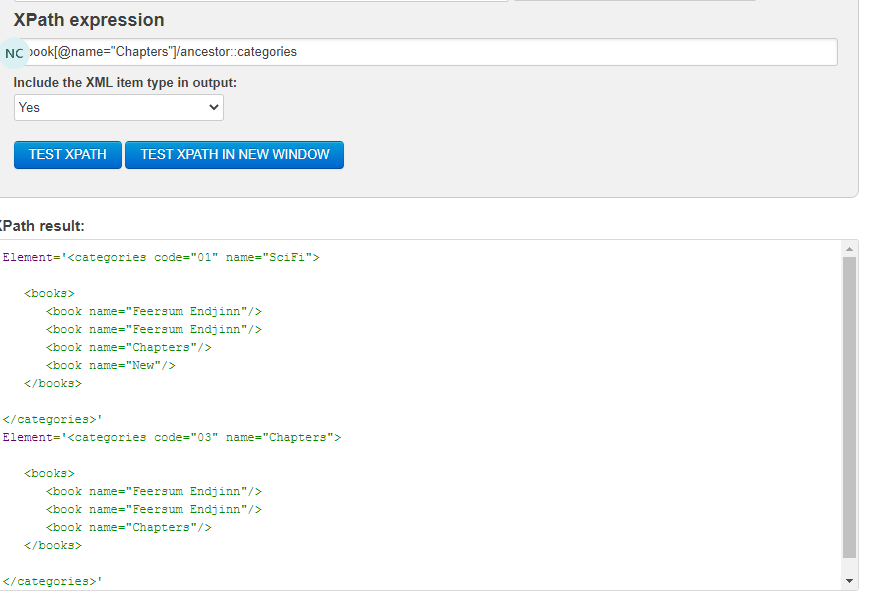
Cps path query already supports //book[@name="Chapters"] querying based on xpath prefix and attributes but it does not yet support /ancestor::bookstore
suggestions for solutions
- Expand regex for existing query/queries to recognize /ancestor postfix and extract the 'schema node identifier' e.g 'categories' or 'bookstore'
- execute the normal query part and either of the xpaths of results to generate a set of unique ancestor (xpaths)
- note; the ancestor can be a list "/categories[@id=value]/" OR it can be a standard container "/bookstore/" we need to support both possibilities
- Execute a get-by-xpath for each ancestor with or without children and amalgamate results