-
Task
-
Resolution: Won't Do
-
 Medium
Medium
-
None
-
None
Kubernetes clusters - here on AWS experience periodic host reconnects - causing issues with distributed pods and running kubectl commands
The problem usually resolves after 10 min
Could be related to the small VMS (3 x 32g at 4 vCores each) - will rerun on a 24 vCore cluster
Cluster was running EFS/NFS
http://jenkins.onap.info/job/oom-cd-master/2855/console
a lot better after 2h
ubuntu@ip-10-0-0-19:~$ kubectl get pods --all-namespaces | grep 0/
onap onap-aaf-586b756997-gnx62 0/1 Running 26 2h
onap onap-dbcl-db-1 0/1 CrashLoopBackOff 9 2h
onap onap-log-kibana-6bb55fc66b-g6fn8 0/1 Running 22 2h
onap onap-nexus-54ddfc9497-q8ztx 0/1 CrashLoopBackOff 8 2h
ubuntu@ip-10-0-0-19:~$ kubectl get pods --all-namespaces | grep 1/2
onap onap-sdc-be-f59ccf7c9-qcsw9 1/2 Running 0 2h
onap onap-sdc-onboarding-be-6656f56dc4-htrqn 1/2 Running 0 2h
have to triage why periodically kubectl starts to fail
2:01:19 onap onap-nexus-54ddfc9497-q8ztx 0/1 CrashLoopBackOff 8 2h 10.42.202.52 ip-10-0-0-210.us-east-2.compute.internal
22:01:19 4 pending > 0 at the 107th 15 sec interval
22:02:29 serializer for text/plain; charset=utf-8 doesn't exist
22:02:45 serializer for text/plain; charset=utf-8 doesn't exist
22:02:45
22:02:45 0 pending > 0 at the 108th 15 sec interval
22:02:45 Error from server (InternalError): an error on the server ("Service unavailable") has prevented the request from succeeding (get pods)
22
michaelobrien [6:17 PM]
back after 10 min and hosts reconnect - will need a section in the cd.sh script to pause when kubectl is busted temporarilly
this is why some healthchecks are not run currently
ubuntu@ip-10-0-0-19:~$ kubectl version
Client Version: version.Info{Major:"1", Minor:"8", GitVersion:"v1.8.10", GitCommit:"044cd262c40234014f01b40ed7b9d09adbafe9b1", GitTreeState:"clean", BuildDate:"2018-03-19T17:51:28Z", GoVersion:"go1.8.3", Compiler:"gc", Platform:"linux/amd64"}
Server Version: version.Info{Major:"1", Minor:"8+", GitVersion:"v1.8.10-rancher1", GitCommit:"66aaf7681d4a74778ffae722d1f0f0f42c80a984", GitTreeState:"clean", BuildDate:"2018-03-20T16:02:56Z", GoVersion:"go1.8.3", Compiler:"gc", Platform:"linux/amd64"}
all right I found a DC that i was able to spin up 4 128G 32 core vms - (so 96 vCores, 384G ram cluster) - installing now
guys part of the issue is that the ELK stack has been failing today to pass HC - so 32 would be 35
17:02:17 ------------------------------------------------------------------------------
17:03:16 Basic Log Elasticsearch Health Check | FAIL |
17:03:16 Test timeout 1 minute exceeded.
17:03:16 ------------------------------------------------------------------------------
17:04:16 Basic Log Kibana Health Check | FAIL |
17:04:16 Test timeout 1 minute exceeded.
17:04:16 ------------------------------------------------------------------------------
17:05:16 Basic Log Logstash Health Check | FAIL |
17:05:16 Test timeout 1 minute exceeded.
looking into it
michaelobrien [6:23 PM]
Basic SDNC Health Check | FAIL |
Resolving variable '${resp.json()['output']['response-code']}' failed: JSONDecodeError: Expecting value: line 1 column 1 (char 0)
jmac [6:24 PM]
That’s weird. No changes have been merged lately
Did all the pods come up?
michaelobrien [6:26 PM]
one of the 3 cluster vms has a lot less pods than the other 2 in rancher
http://master.onap.info:8880/env/1a7/infra/hosts
maybe a couple of the pods are huge
here is the list of failures
ubuntu@ip-10-0-0-19:~/oom/kubernetes/robot$ kubectl get pods --all-namespaces | grep 0/
onap onap-aaf-586b756997-gnx62 0/1 Running 33 3h
onap onap-dbcl-db-1 0/1 Running 14 3h
onap onap-log-kibana-6bb55fc66b-g6fn8 0/1 Running 26 3h
onap onap-nexus-54ddfc9497-q8ztx 0/1 CrashLoopBackOff 15 3h
onap onap-sdnc-portal-696f4979c9-nwgzg 0/1 CrashLoopBackOff 6 13m
ubuntu@ip-10-0-0-19:~/oom/kubernetes/robot$ kubectl get pods --all-namespaces | grep 1/2
onap onap-sdc-be-f59ccf7c9-qcsw9 1/2 Running 0 2h
onap onap-sdc-onboarding-be-6656f56dc4-htrqn 1/2 Running 0 3h
a lot better than my usual 13 falures
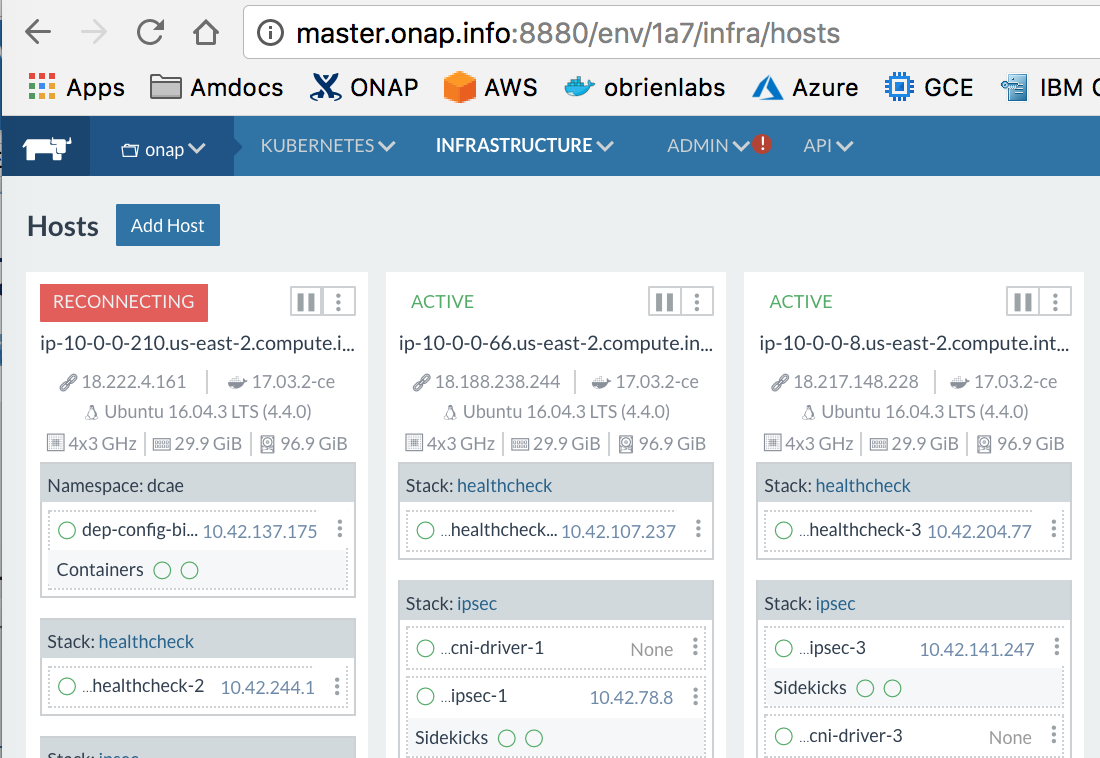
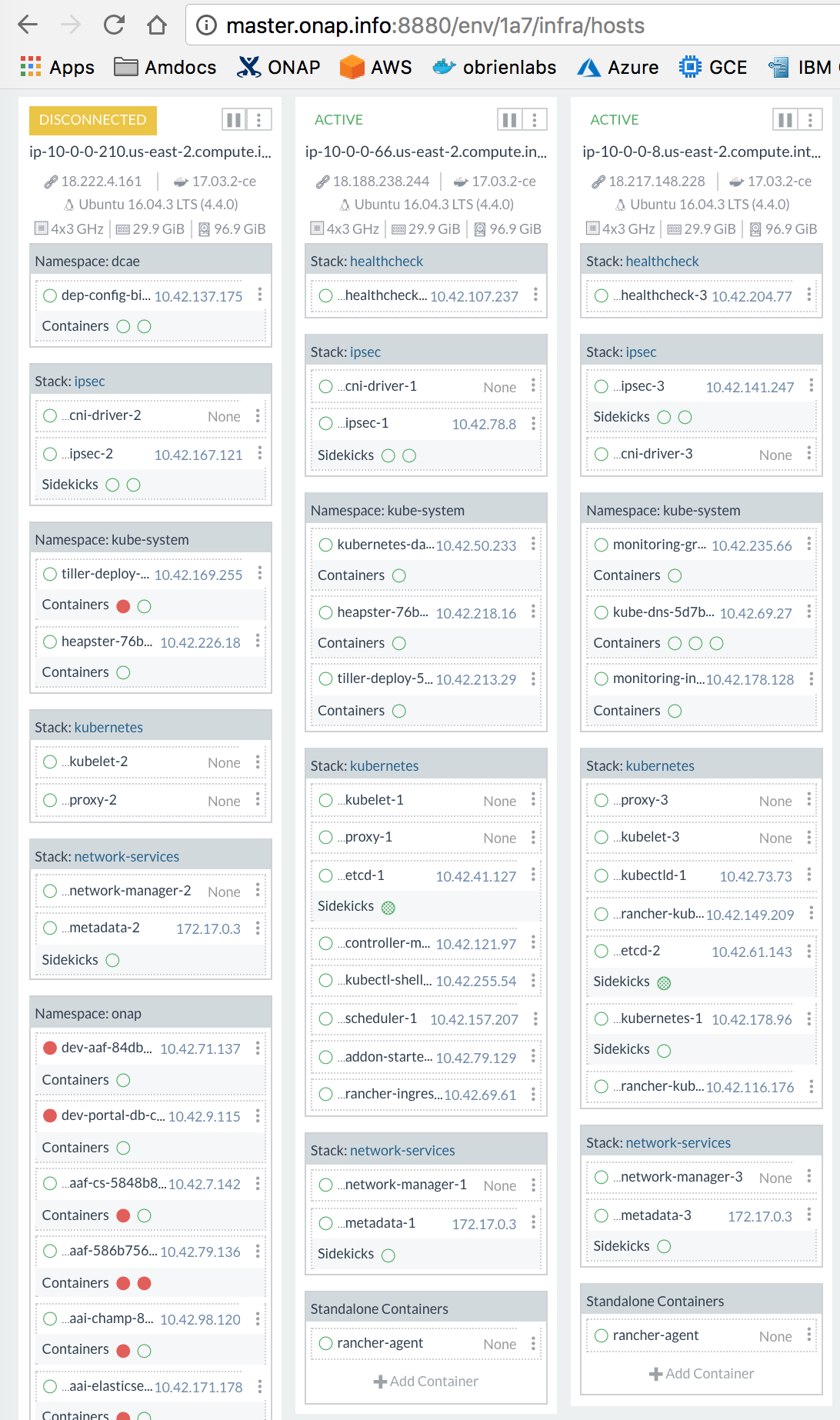
- relates to
-
-
- Closed
-