-
 Epic
Epic
-
Resolution: Won't Do
-
 Medium
Medium
-
None
-
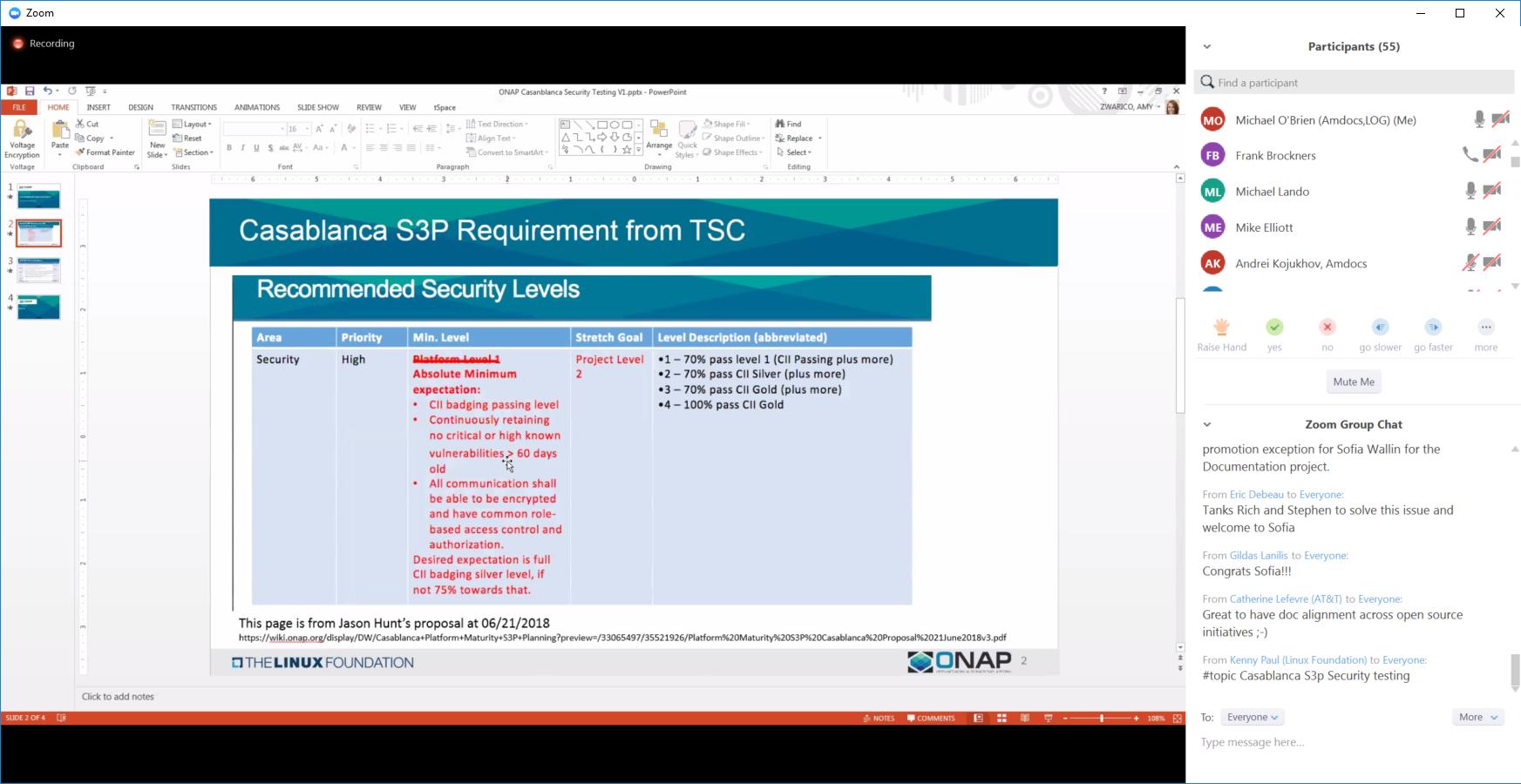
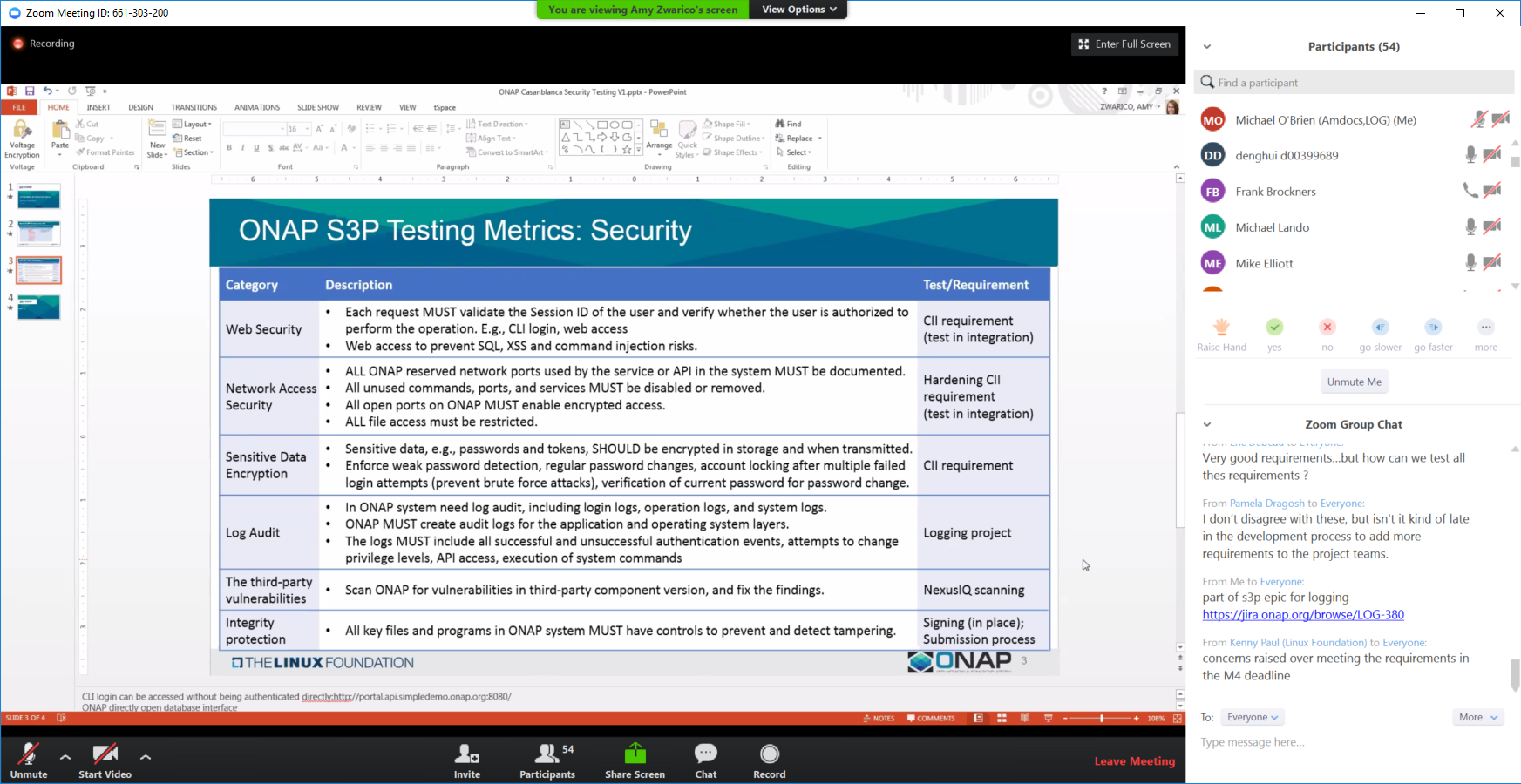
Platform Maturity: Performance, Stability, Resiliency, Scalability
https://wiki.onap.org/display/DW/S3P
+) Performance optimization of the ELK stack in OOM
https://lists.onap.org/pipermail/onap-discuss/2018-May/009822.html
See LOG-181 (DaemonSets), LOG-376 (temporary ReplicaSet:3)
An idle ONAP deployment pushes 30+ logs/sec (1+ Gb/day) into the ELK stack – we are going through optimizing the stack.
- Logstash was saturating a single VM of a cluster before we put in a temp fix to up the replicaSet from 1 to 3 – there is a change under test/review for a DaemonSet (1 container/vm) – we will discuss this
- Logstash issue - https://jira.onap.org/browse/LOG-376
- S3P ELK epic - https://jira.onap.org/browse/LOG-258
- A root-cause-analysis will be attempted both for the southbound filebeat push of logs into logstash and the northbound pull from elasticsearch during indexing
- The 30 logs/sec causes periodic vCore peaks of 7
- The full resource optimization of all of ONAP is being started by Mike E. under https://jira.onap.org/browse/OOM-927 to start - we will work with these changes
- The resource requirements of most of the components in OOM are defaulted/commented – we will look at the ELK containers in this session
- Fine tuning the CPU/RAM only for ELK may be problematic unless we tune all ONAP components together (prioritize) – in this session we will just do the 3 log containers
- If we have time we will cover off
- Use of a load balancer serviceType – we are taking on faith that the current service distributes load properly on the DaemonSet
- GC heap usage – if it is an issue
- Elasticsearch shard settings (beyond defaults)
- Oscillation behavior under a forced 2g or 2core limit stop/starting container
- Determine the sweet spot for horizontal clustering of es and ls
- Determine the effect of cpu/ram resource limits on other pods in particular vms
- Elasticsearch messagebroker usage – if es is overloading ls
- Future: ElasticSearch as a service for clamp/aai/log
Check backpressure setting against filebeat
Shane: hold off on processing in ES, incrementally process to identify the 7 core bottleneck
for RCA - back off on heartbeat error logs coming from cluster logs in components - prioritize real onap logs - not infrastructure
- blocks
-
LOG-376 Logstash full saturation of 8 cores with AAI deployed on one of the quad 8 vCore vms for 30 logs/sec - up replicaSet 1 to 3 or use DaemonSet
-

- Closed
-
-
LOG-507
POMBA as RI/Demo of Casablanca Logging spec/library compliance - deployment/helm and runtime
-
- Closed
-
- is blocked by
-
LOG-154
Platform Maturity: Beijing required security badging procedure
-
- Closed
-
-
 LOG-992
RKE 0.16 / Docker 18.06 for ONAP installation - migrate from Rancher for Dublin - script support
LOG-992
RKE 0.16 / Docker 18.06 for ONAP installation - migrate from Rancher for Dublin - script support
-
- Closed
-
-
LOG-258
S3P ELK stack performance and clustering
-
.
Must be fixed in any of the upcoming builds and should be included in the current release.")
- Closed
-
-
-
- Closed
-
-
LOG-651
LOG: address failing jenkins jobs
-
- Closed
-
- is duplicated by
-
LOG-258
S3P ELK stack performance and clustering
-
- Closed
-
-
LOG-146
ELK stack performance testing under logging library
-
- Closed
-
- relates to
-
-
- Closed
-
-
LOG-157
S3P Events, Metrics, Monitoring
-
- Closed
-
-
LOG-366
OOM Volumetrics - docker image sizes
-
- Closed
-
-
LOG-436 Log file rotation - to avoid saturating a particular VM
-
- Closed
-
-
LOG-181
Use DaemonSets for logging - Logstash
-
- Closed
-
-
LOG-494
Use Search Guard Community Edition for TLS REST encryption
-
- Closed
-
-
LOG-876
S3P: Logging for Core Service/VNF state and transition model - Deutsche Telekom and Vodafone
-
- Closed
-
-
INT-597 Review container images best practices - Logging team
-
- Closed
-
-
OOM-346
Platform Resiliency (Recoverability, High-Availability, Geo-Diversity)
-
- Closed
-
1.
|
Kubernetes log rotation strategy for /var/lib/docker/container/ |
|
Closed | pau2882 |
2.
|
Baseline standard log load |
|
Closed | pau2882 |
3.
|
Kibana must wait for elasticsearch to pass readiness/liveness |
|
Closed | pau2882 |