-
Bug
-
Resolution: Done
-
 Highest
Highest
-
None
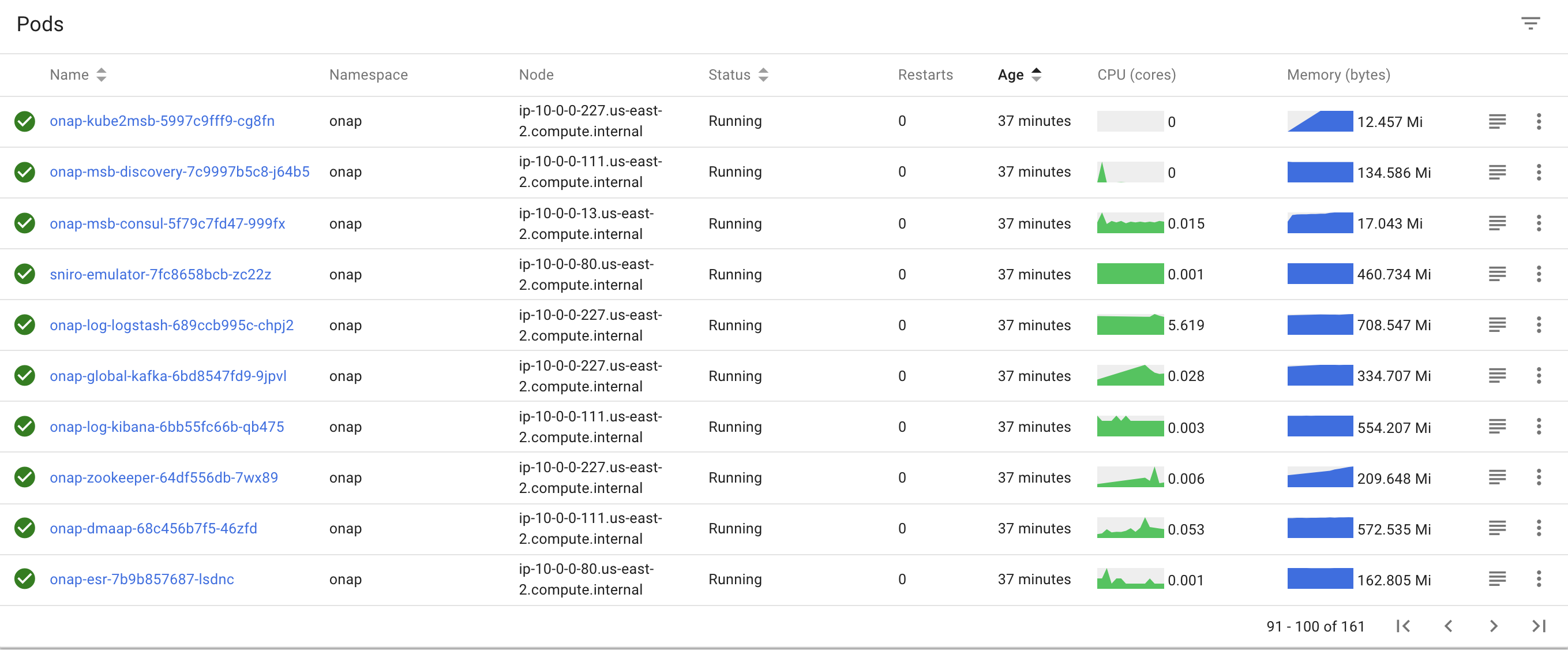
![]() 20190109
20190109
from aai team
https://wiki.onap.org/display/DW/2019-01-17+AAI+Developers+Meeting+Open+Agenda
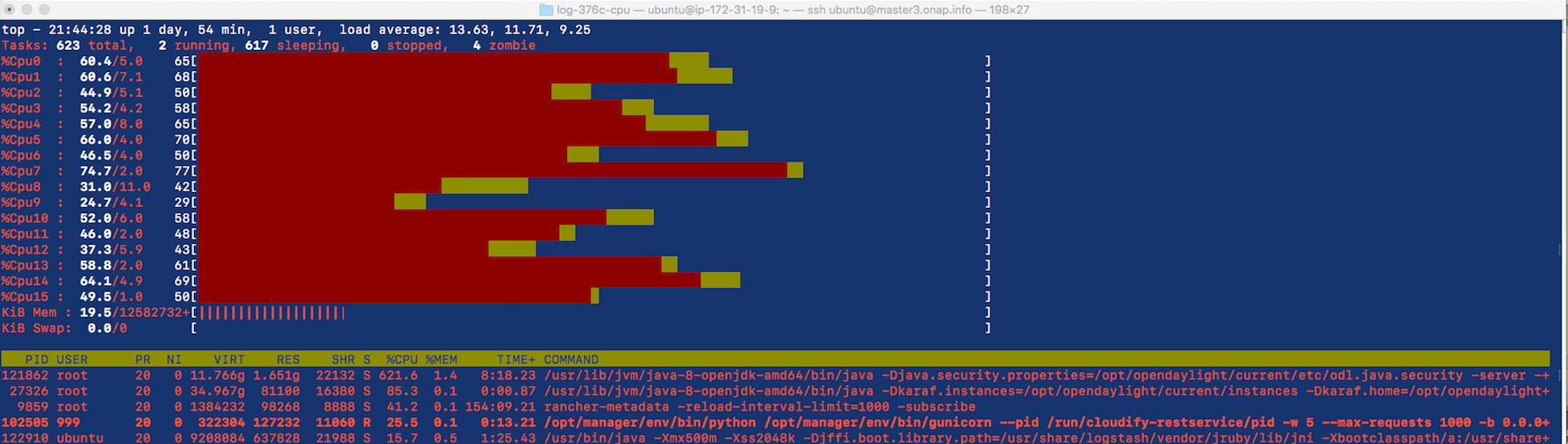
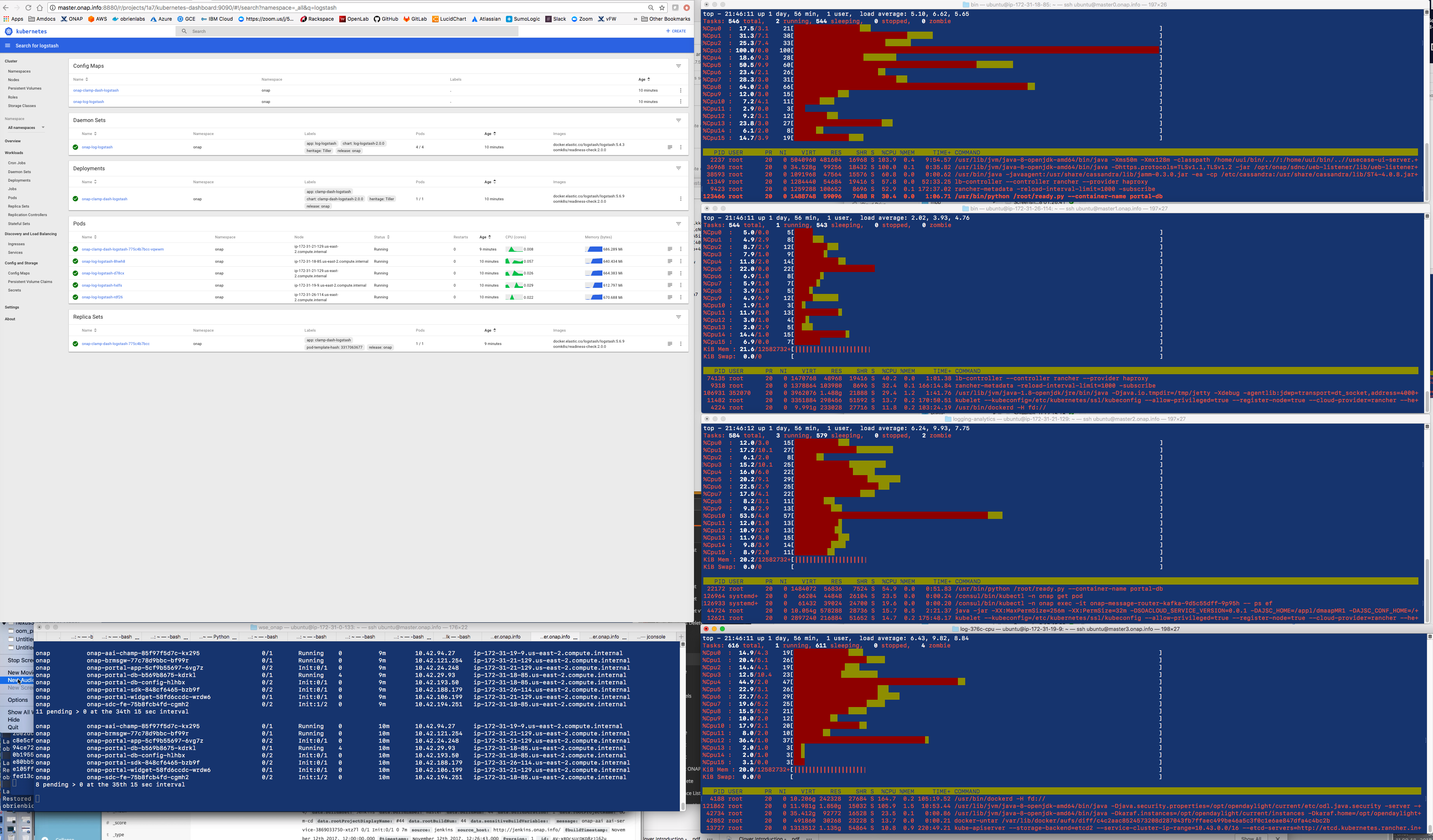
"hector has discovered that the stress test jar (liveness probe?) in aai-cassandra is hammering the cpu/ram/hd on the vm that aai is on - this breaks the etcd cluster (not the latency/network issues we suspected that may cause pod rescheduling) "
![]() 20181017: update - reopen or re-raise AAI/Logstash specific JIRA for Dublin - in
20181017: update - reopen or re-raise AAI/Logstash specific JIRA for Dublin - in LOG-707 - as the issue is more of an AAI to logstash issue
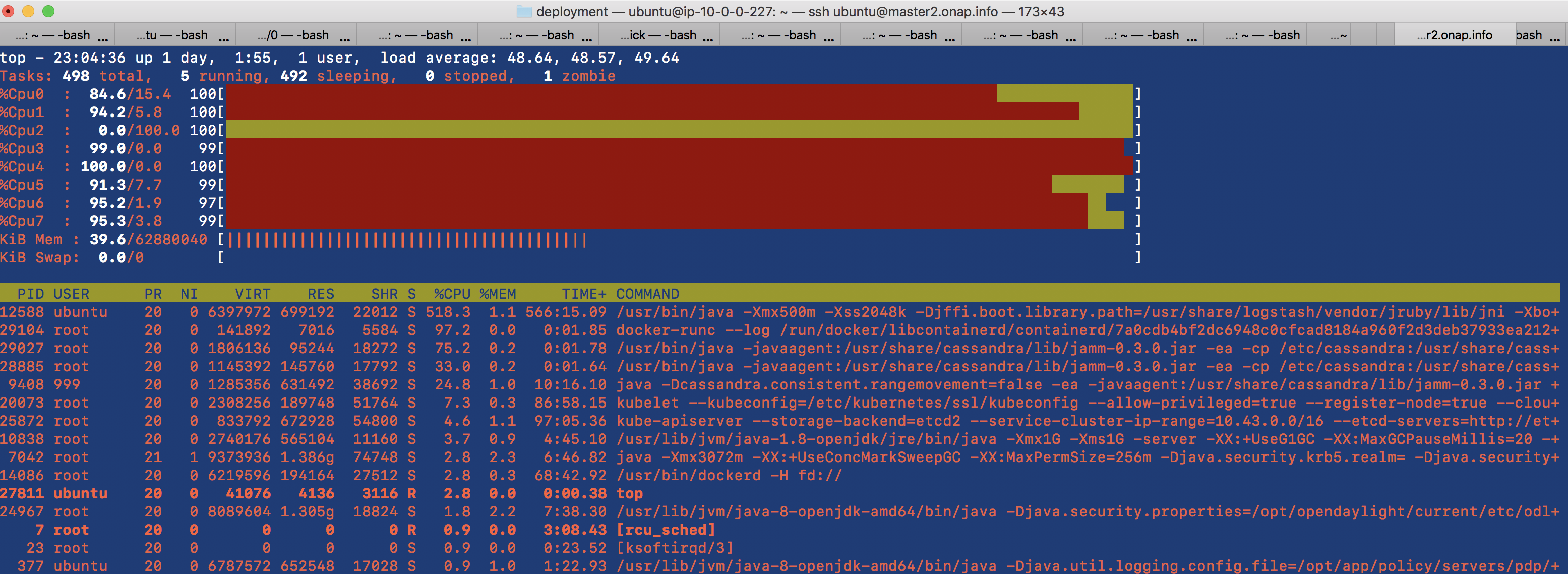
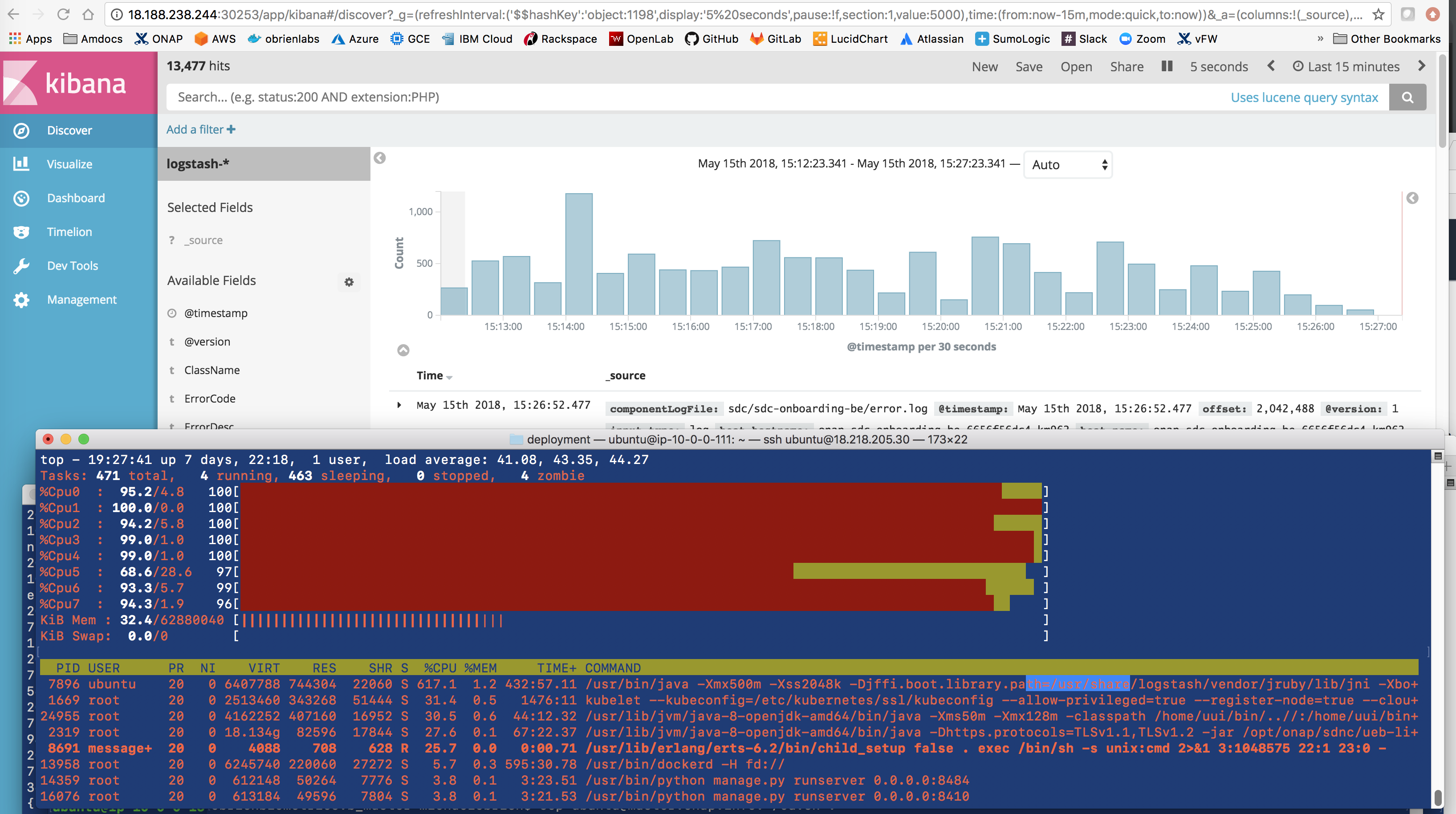
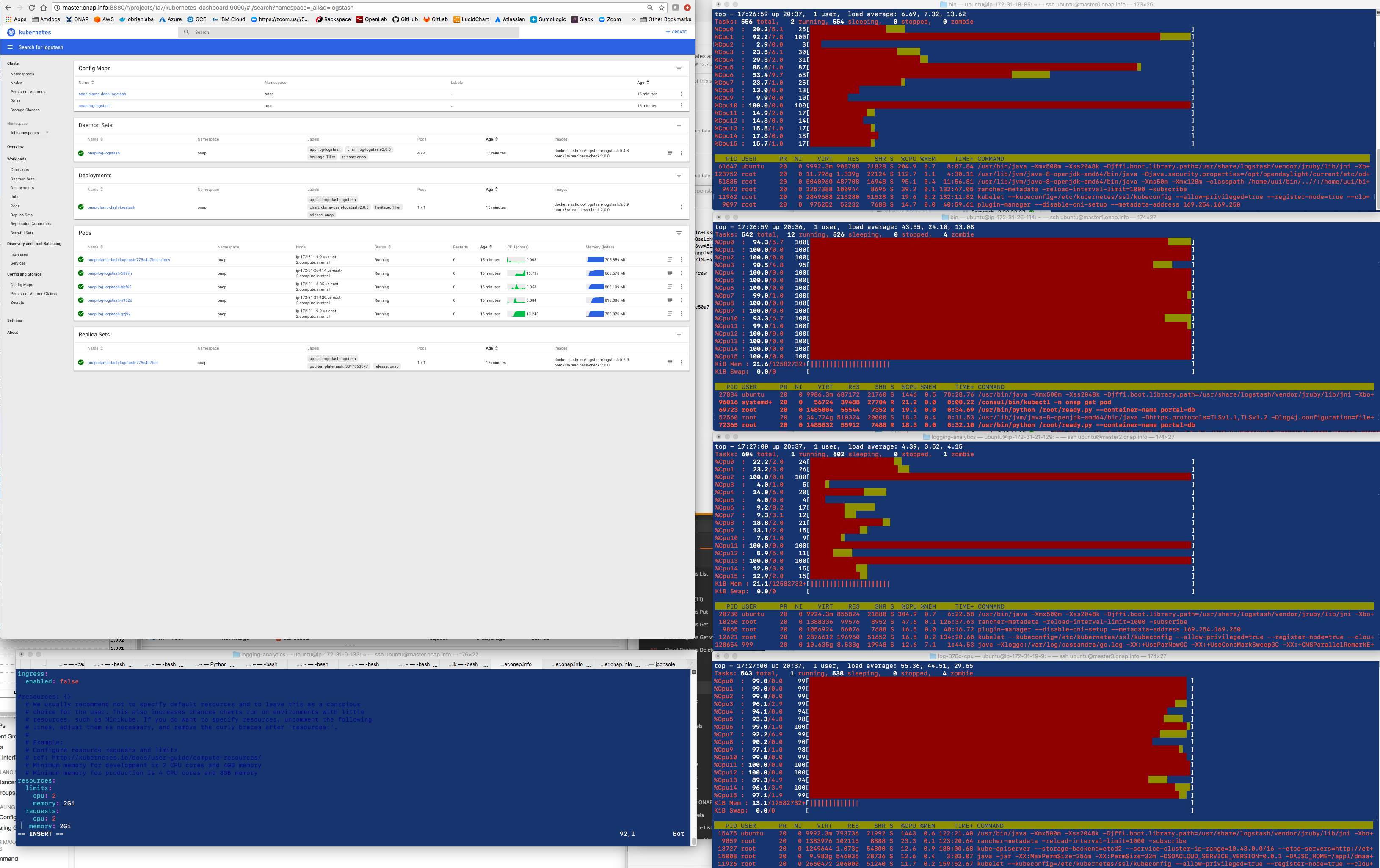
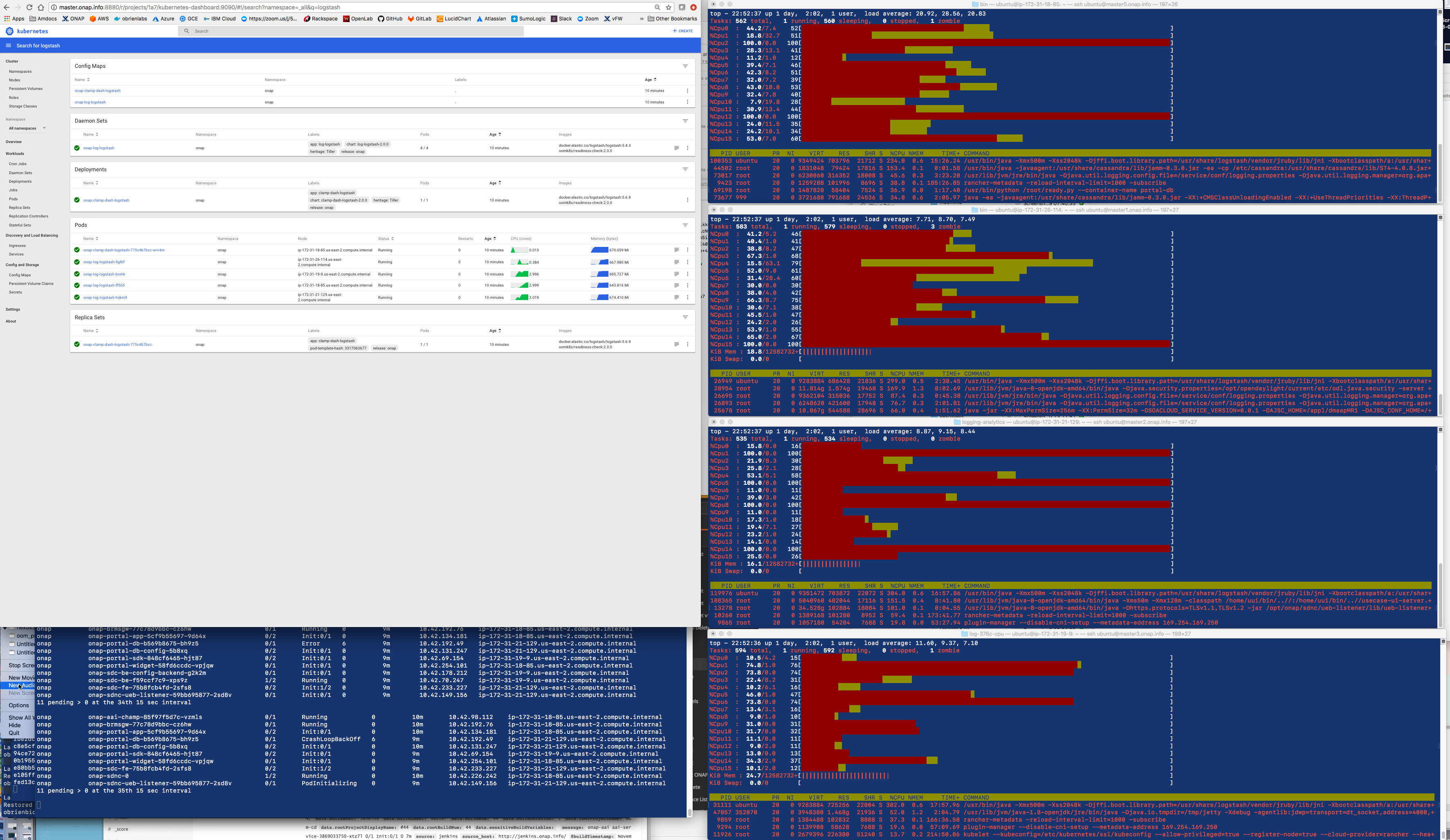
Need to find out which container - it is the logstash one - mine
12588 ubuntu 20 0 6397972 699192 22012 S 578.1 1.1 567:55.27 /usr/bin/java -Xmx500m -Xss2048k -Djffi.boot.library.path=/usr/share/logstash/vendor/jruby/lib/jni -Xbo+
http://jenkins.onap.info/job/oom-cd-master/2897/console
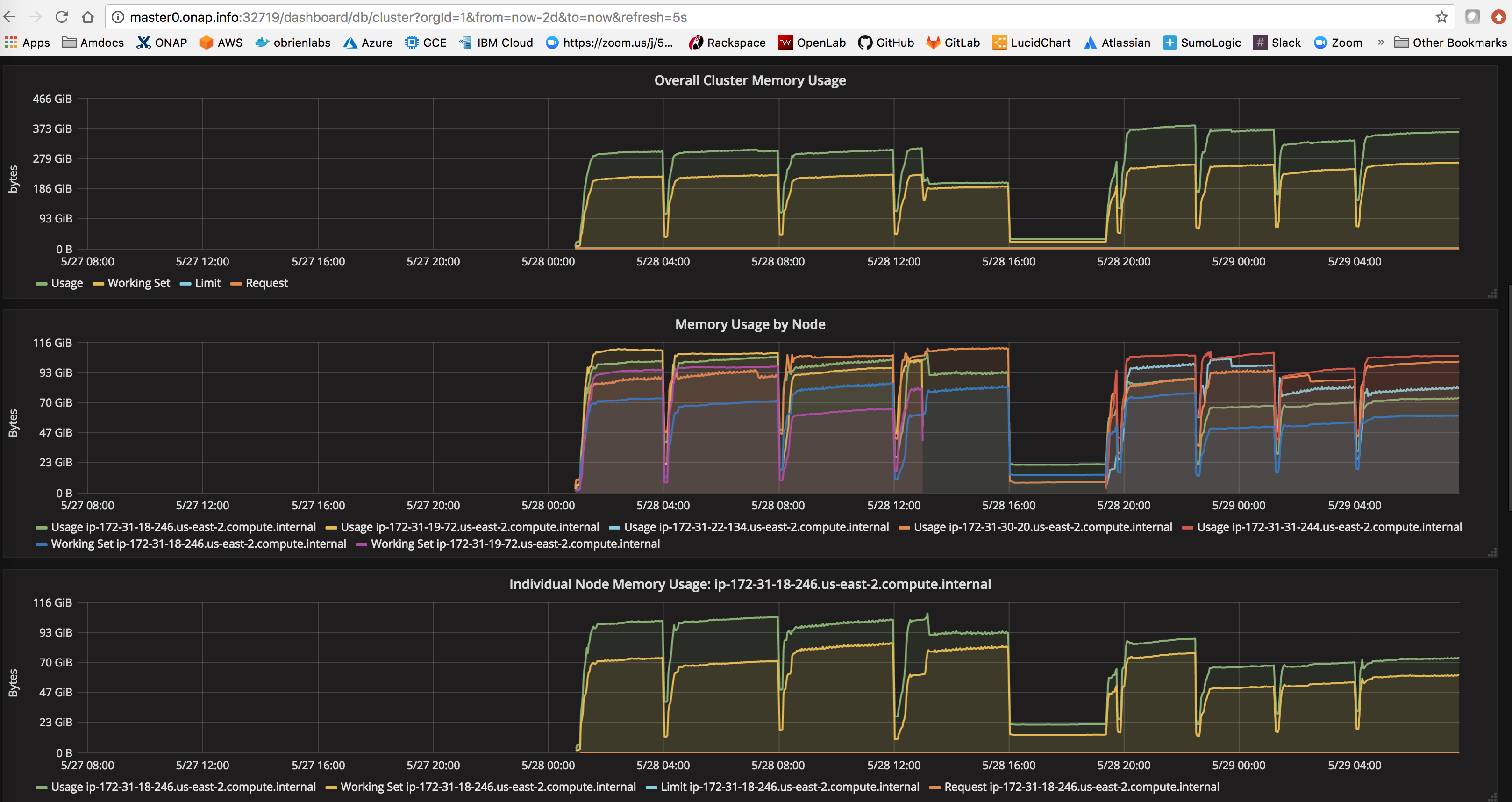
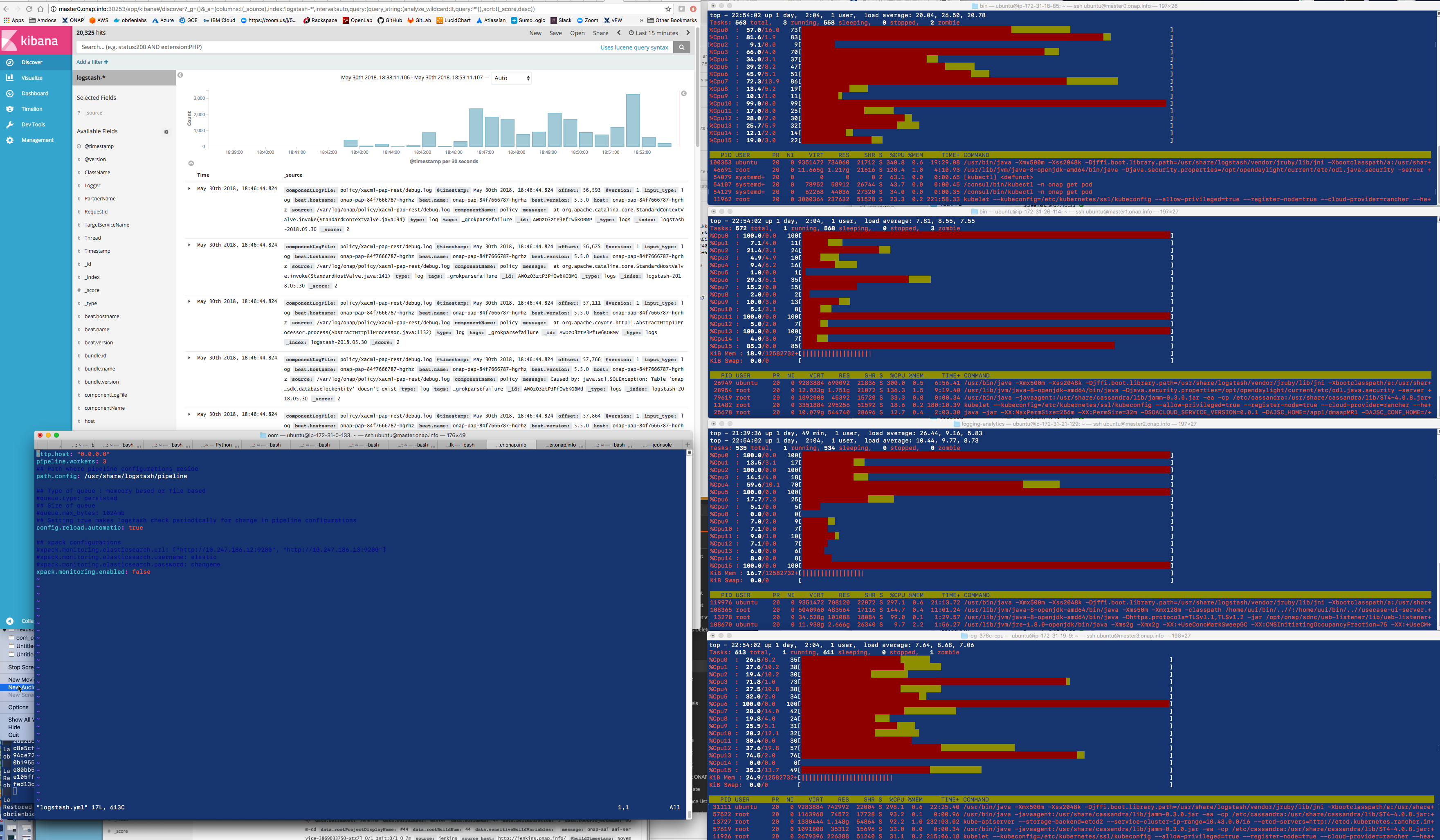
![]() find out what the reason is for the saturation - is it excessive logs from example the cluster heartbeat from all the db clusters
find out what the reason is for the saturation - is it excessive logs from example the cluster heartbeat from all the db clusters
or a misconfiguration of the resource section
it looks like logs are still being processed up to 4 min after they come into logstash - getting an average of 200-400 logs per 30 sec on

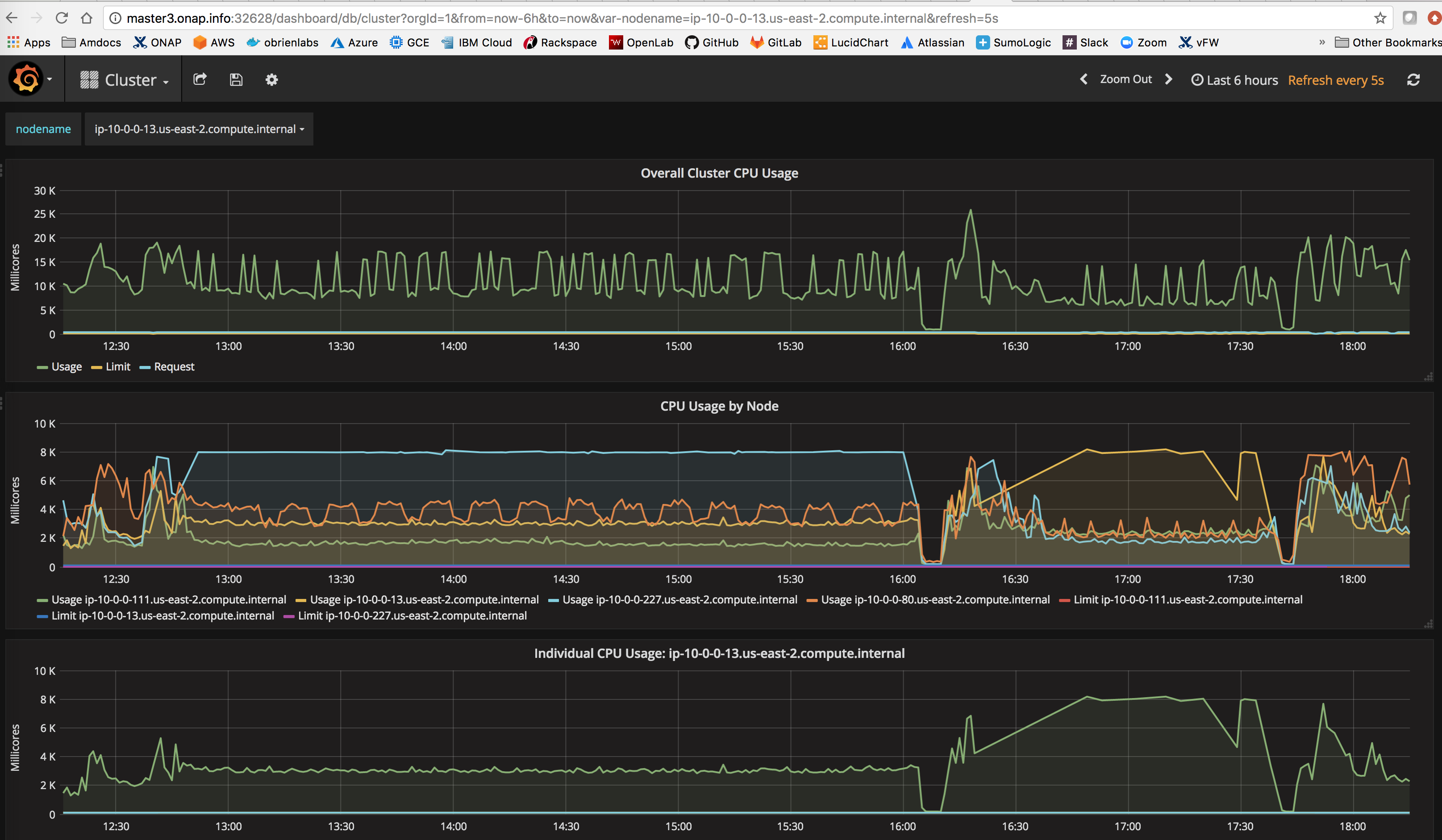
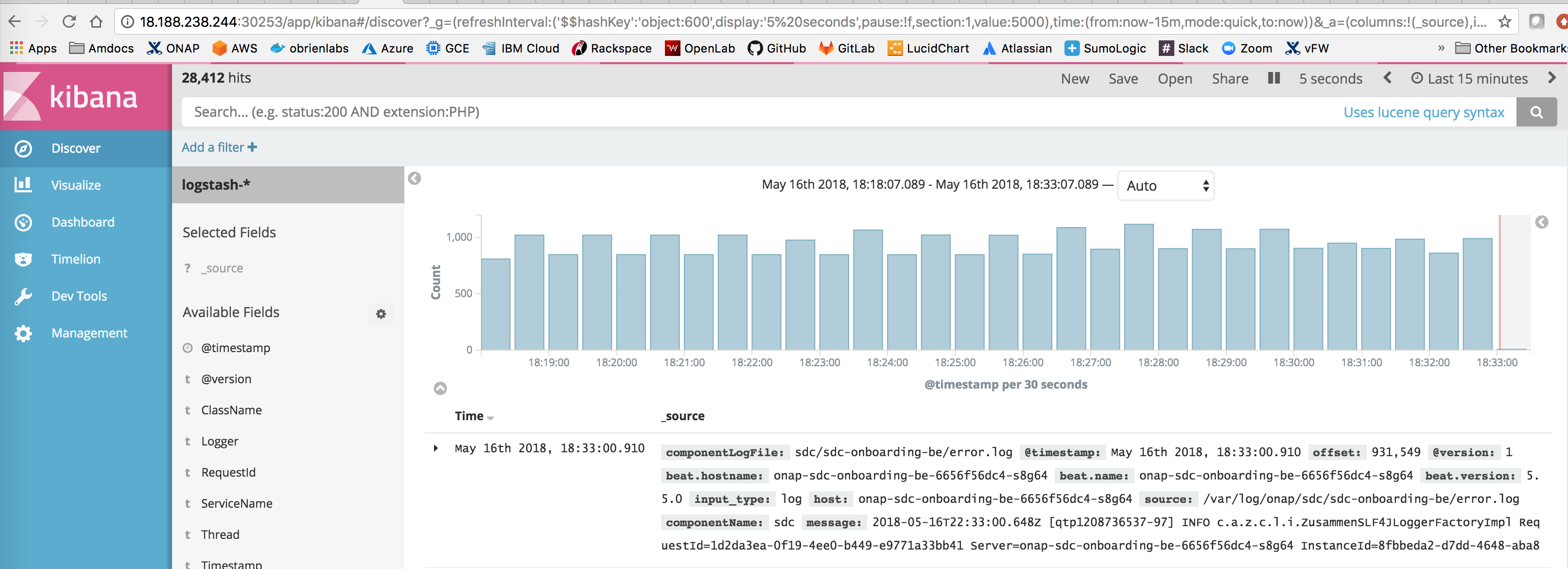



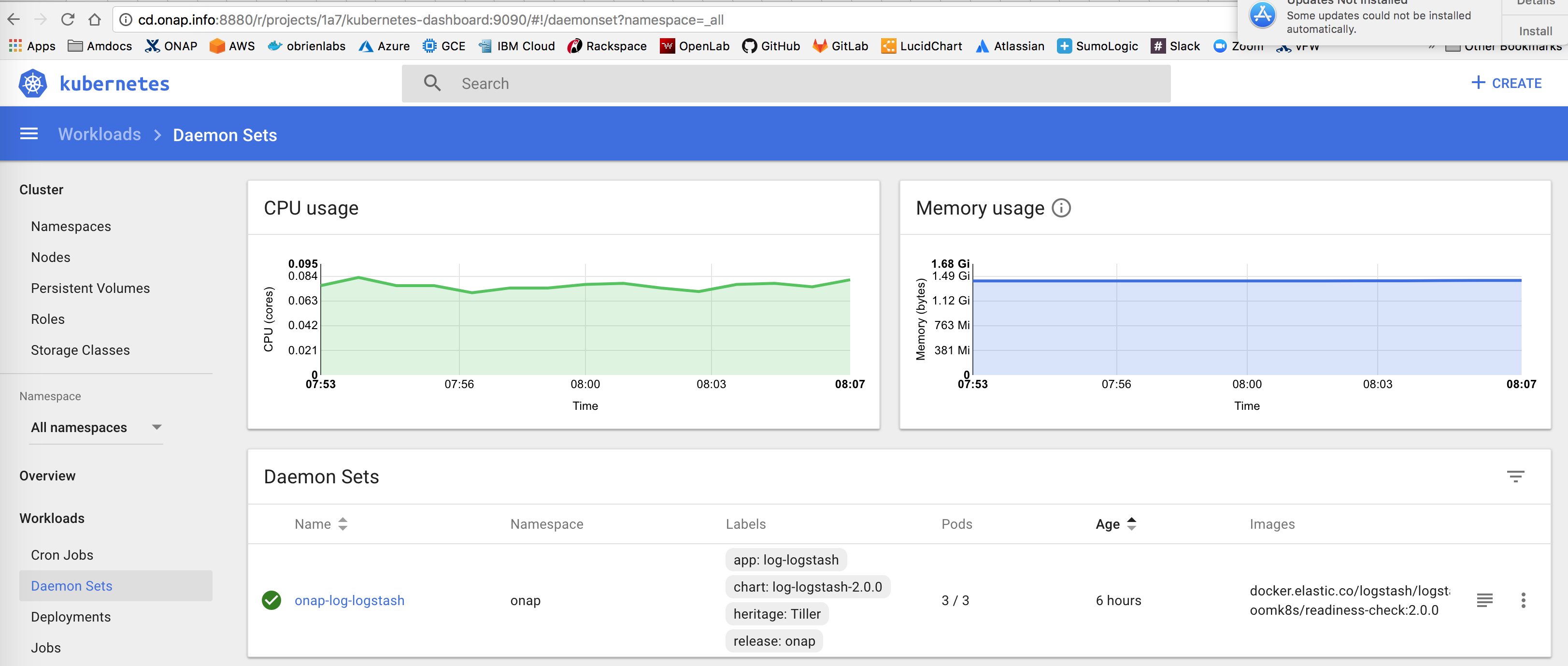

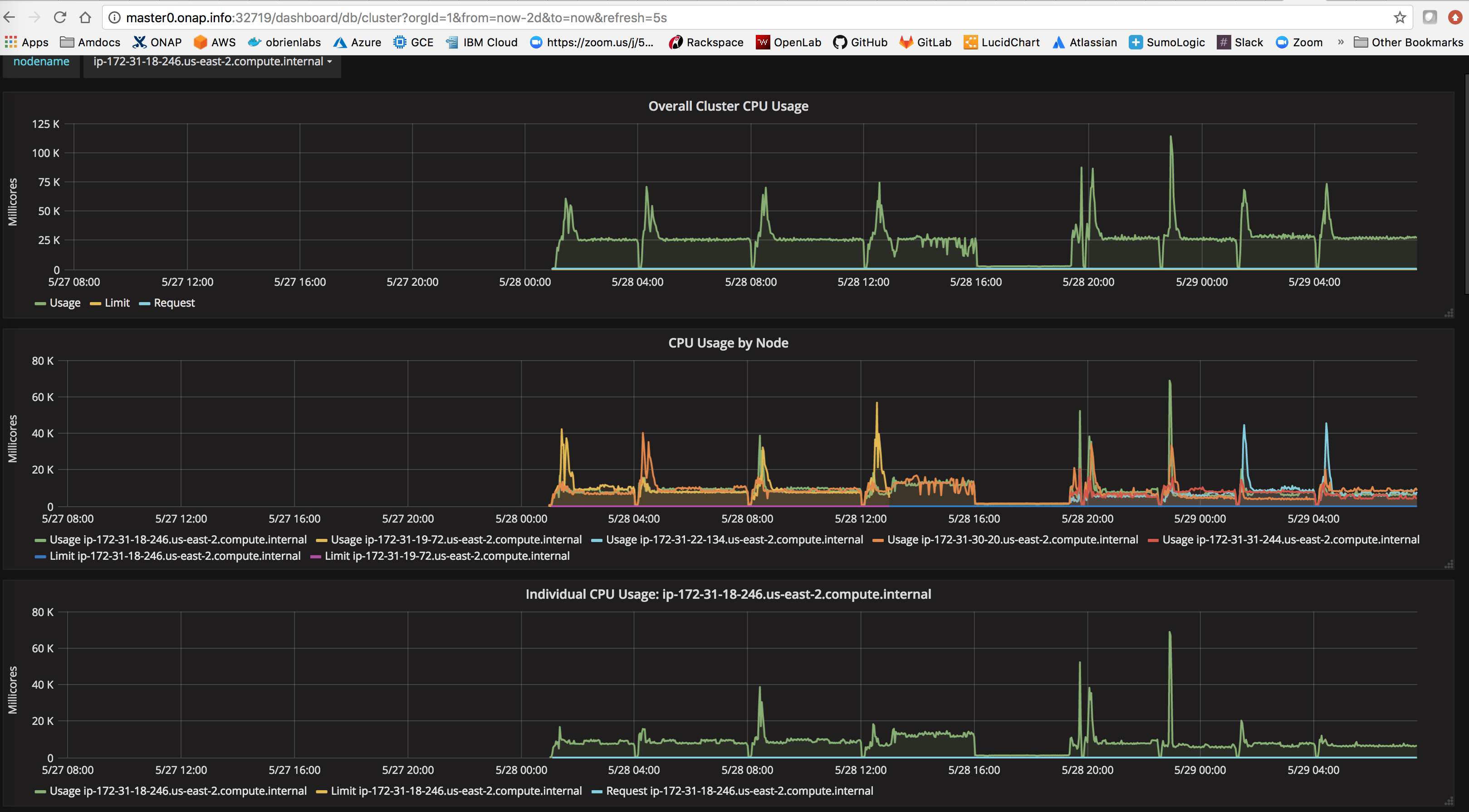


- blocks
-
LOG-915 Reduce Logstash core limit to 1 from 3 until LOG-LS and AAI-CS perf issue on the same VM is determined
-
.
Must be fixed in any of the upcoming builds and should be included in the current release.")
- Open
-
-
 LOG-841
Logstash container - use a label to distribute the ReplicaSet instead of DaemonSet
LOG-841
Logstash container - use a label to distribute the ReplicaSet instead of DaemonSet
-

- Closed
-
-
-
- Closed
-
- duplicates
-
-
- Closed
-
- is blocked by
-
 LOG-181
Use DaemonSets for logging - Logstash
LOG-181
Use DaemonSets for logging - Logstash
-
- Closed
-
-
LOG-258
S3P ELK stack performance and clustering
-
- Closed
-
-
-
- Closed
-
-
LOG-380
Platform Maturity: Performance, Stability, Resiliency, Scalability
-
- Closed
-
-
-
- Closed
-
- is duplicated by
-
-
- Closed
-
- relates to
-
LOG-877
S3P: Logging streaming/format alignment for dublin - China Telecom, Deutsche Telekom, Vodafone
-
- Closed
-
-
-
- Closed
-
-
LOG-876
S3P: Logging for Core Service/VNF state and transition model - Deutsche Telekom and Vodafone
-
- Closed
-
-
-
- Closed
-
-
-
- Closed
-
-
LOG-157
S3P Events, Metrics, Monitoring
-
- Closed
-
-
OOM-758
Common Mariadb Galera Helm Chart to be reused by many applications
-
- Closed
-
-
OOM-927
Need a production grade configuration override file of ONAP deployment
-
- Closed
-
-
OOM-1153 Resource Limits for log
-
- Closed
-
-
-
- Closed
-
-
VVP-130
DEV mode dev.yaml override for all remaining ReplicaSet counts still above 1
-
- Closed
-
-
-

- Closed
-
- links to
- mentioned in
-
Page Loading...
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-