-
Task
-
Resolution: Done
-
.
Must be fixed in any of the upcoming builds and should be included in the current release.") High
High
-
None
Meeting Videos: https://wiki.onap.org/display/DW/CD+-+Continuous+Deployment
![]() 20181026: LF Ticket 62287 is tracking this request
20181026: LF Ticket 62287 is tracking this request
Meets 1230 EDT (GMT-5) Thu https://zoom.us/j/7939937123
https://lists.onap.org/g/onap-discuss/topic/cd_task_force_tsc_25_meetings/29416249?p=,,,20,0,0,0::recentpostdate%2Fsticky,,,20,2,0,29416249
![]() POCs
POCs
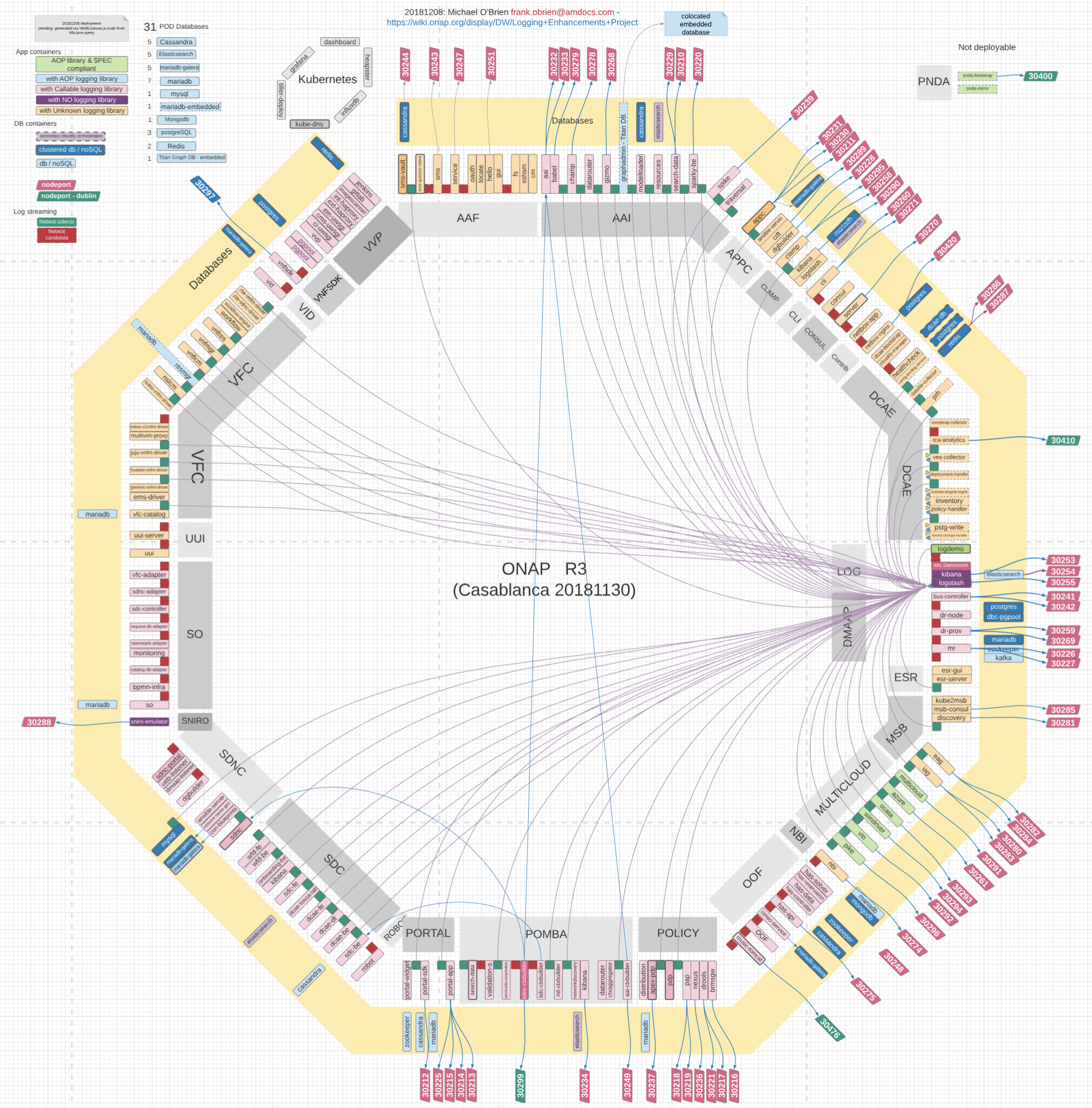
Integration team: 2018
gwu - full onap system 13 vms - freq: master once a day
http://onapci.org/grafana/d/8cGRqBOmz/daily-summary?orgId=1
https://github.com/garyiwu/onap-lab-ci
Logging/OOM Team: 201710
michaelobrien - partial onap system 1 vm - freq: hourly for 3 pod - 6 hours for full onap deploy 256G vm
http://kibana.onap.info:5601/app/kibana#/dashboard/AWAtvpS63NTXK5mX2kuS
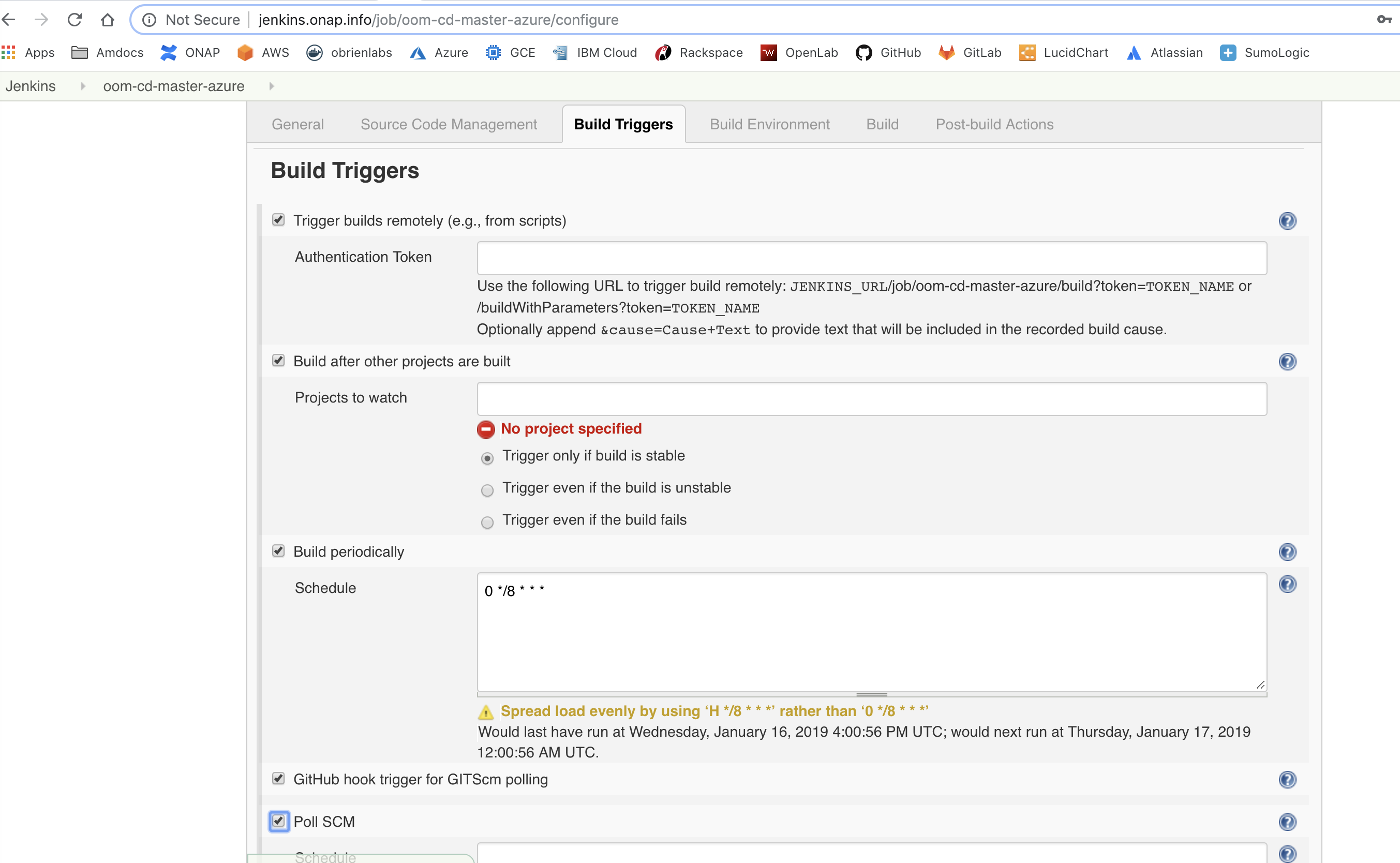
http://jenkins.onap.info/job/oom-cd-master2-aws/
http://jenkins.onap.info/job/oom-cd-master/
https://git.onap.org/logging-analytics/tree/deploy
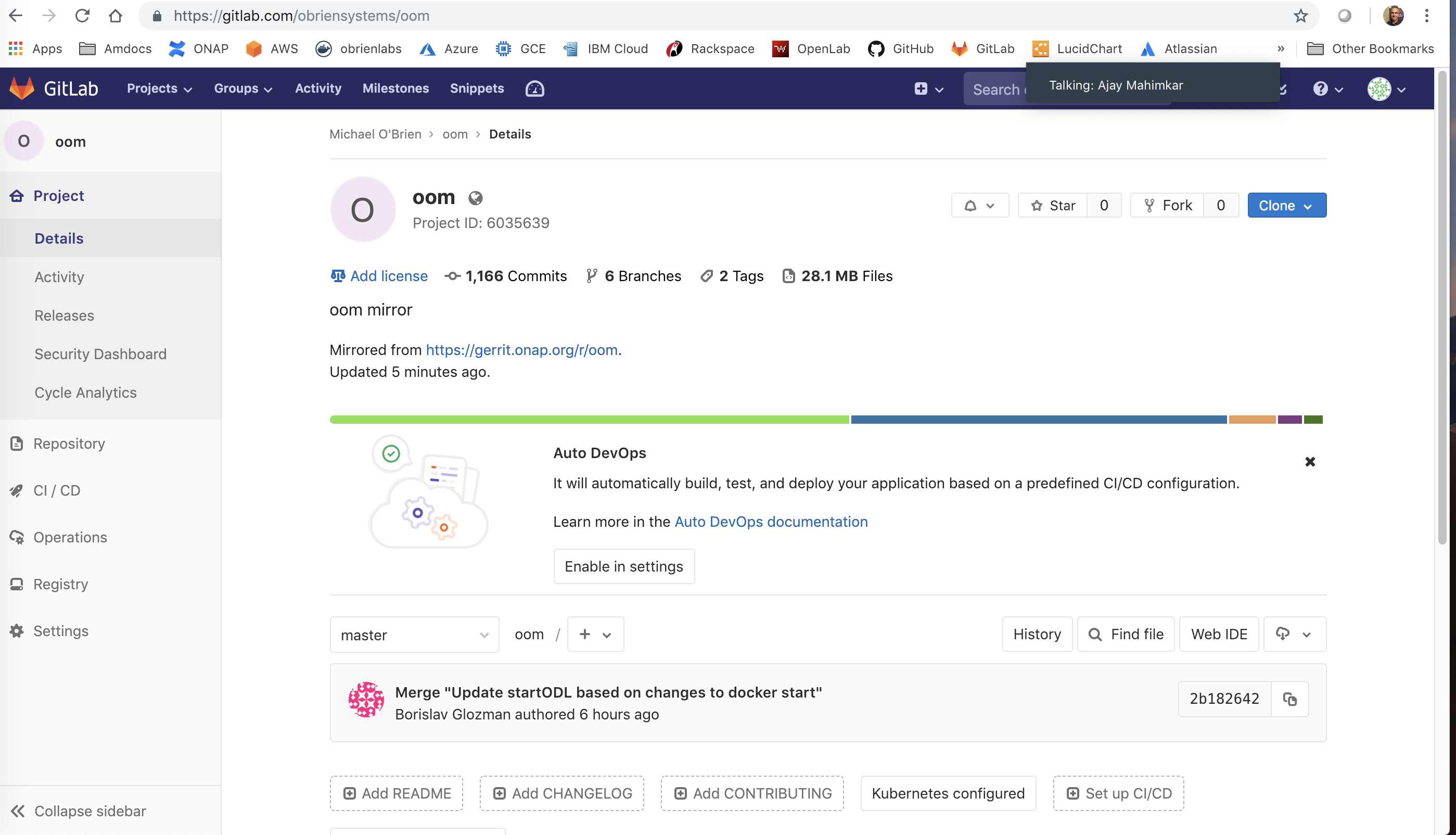
GITLAB OOM mirror for 2nd CD pipeline
https://gitlab.com/obriensystems/oom
Orange Labs 201901
https://gitlab.com/Orange-OpenSource/lfn/onap/onap_oom_automatic_installation/pipelines/44398686
https://gitlab.com/Orange-OpenSource/lfn
Working E2E demo: https://wiki.onap.org/display/DW/CD+-+Continuous+Deployment#CD-ContinuousDeployment-20190131-OrangeCDdemofromSylvainDesbureaux
Orange demo from last week on https://wiki.onap.org/display/DW/CD+-+Continuous+Deployment#CD-ContinuousDeployment-20190131-OrangeCDdemofromSylvainDesbureaux
example on https://gerrit.onap.org/r/#/c/77660/
- flow:
Existing flow - gerrit commit on the oom repo for a particular component like so, aai - keyed by Issue-ID Jira - helm-verify jjb jenkins job currently runs - reports +1/-1 - review is merged - helm verify runs again on master - no helm deploy Proposed flow 1 - gerrit commit on the oom repo for a particular component like so, aai - keyed by Issue-ID Jira - helm-verify jjb jenkins job currently runs - reports +1/-1 - manual magic word "run-helm-deploy" will kick in a helm-deploy jjb job that deploys robot and the particular pod to a 16-32g VM (preconfigured with rancher as a single node) - how? jenkins will run a remote ssh shell to a server using a cached key - a cd.sh script will need to be written - see the 2 pocs below already running - reports +1/-1 if healthcheck for that component passes after 20 min - parse the logs from jenkins - scripts to bring up k8s/helm/docker - see links in comments Caveats: 3 types of tests (docker image tag, kubernetes chart/job/config changes) - docker image tag changes will require that the image is in nexus3 already - ideally only oom repo changes will be in phase 1 Proposed flow 2 later - gerrit commit on the oom repo for a particular component like so, aai - keyed by Issue-ID Jira - helm-verify jjb jenkins job currently runs - reports +1/-1 - same helm-install jjb job again is automatically triggered and reports back a +1/-1 after 20 min - based on # of vms - jobs can be parallelized or batched (report -1/+1 to the batch - but only 1+ are at fault
Task Force: Michael O'Brien, Gildas, Christophe Closset, Jessica, Jeremy,
https://wiki.onap.org/display/DW/Development+Procedures+and+Policies?focusedCommentId=25437277#DevelopmentProceduresandPolicies-MagicWords
Linux Foundation Ticket: 62287
Use labs if they have public non-VPN access - https://wiki.onap.org/display/DW/Physical+Labs
![]() Use cases
Use cases
- OOM docker image tag update
https://gerrit.onap.org/r/#/c/75910/ - OOM chart configuration change
https://gerrit.onap.org/r/#/c/75479/
(essentially at a minimum the CD deploy does)
kubectl get pods --all-namespaces and oom/kubernetes/robot$ sudo ./ete-k8s.sh onap health
Ultimate Main Goal: prevent to merge code that has not been tested in a CD environment.
Realistic code: test merged code in a CD environment.
![]() 20181015 notes: glanilis michaelobrien ChrisC
20181015 notes: glanilis michaelobrien ChrisC
- when to run: only after a successfull helm verify (before code is merged)
example https://jenkins.onap.org/job/oom-master-merge-helm/289/
had a +1 - Q: if the LF would like a separate CDBuilder job to run after or do as part of the current jobbuilder
"Verified +1 ONAP Jobbuilder" - recommend a single VM deployment for 1 pod - not a full ONAP system yet
(for example - the commit is under LOG-NNN
so we run the command with a --set log.enabled=true - the rest of onap is false likesudo helm install local/onap -n onap --namespace onap -f onap/resources/environments/disable-allcharts.yaml --set log.enabled=true
example http://kibana.onap.info:5601/app/kibana#/dashboard/AWAtvpS63NTXK5mX2kuS
- Timing should be <20 min for one pod to helm install and run healthcheck
- Concurrency limit (as a result of multiple gerrit merges within a period) - ask for 4
- LF: servers # and capacity (13 x 16Gb for full onap, 1x 16Gb for a particular component)
(vCPU limits are not enforced yet - but in the future a component like pomba with 11 containers using 10G ram will need 2 x 11 for example vCPUs) - current vCPU limit is 2 - a fraction of a vCPU (10% of a core per container) - full system between 32 and 64 cores - HD need 40G per VM for K8S system and 10G for /dockerdata_nfs - a full deploy is 90G on master and 50g on each cluster VM's
Numbers: full 13x16 = 700G total HD , one component = 90G (single VM) - access (public not VPN) from jenkins jobs
- pilot project
- LF: work on JJB to continue past existing helm-verify
- LF: to see the outcome of the particular helm install - like we get the +1 in for example https://gerrit.onap.org/r/#/c/70486/
- optional nice to have gwu kibana view like in http://onapci.org/grafana/d/8cGRqBOmz/daily-summary?orgId=1
![]() Community
Community
https://docs.opnfv.org/en/latest/submodules/releng-xci/docs/xci-overview.html#xci-overview
investigate ansible based https://zuul-ci.org/
https://jenkins.rook.io/blue/organizations/jenkins/rook%2Frook/detail/master/559/pipeline/




- blocks
-
TSC-92 Casablanca RM branch stability before 3.0.1-ONAP tagging - helm deploy/hc before merging
-
- Closed
-
-
-

- Closed
-
- is blocked by
-
 COMMON-27
ONAP Docker images and base images should be ONAP controlled
COMMON-27
ONAP Docker images and base images should be ONAP controlled
-
- Open
-
-
LOG-310
Gitlab CI/CD via OOM repo mirroring
-
- Closed
-
-
-
- Closed
-
-
-
- Closed
-
-
-
- Closed
-
-
-
- Closed
-
-
-
- Closed
-
-
INT-586
Improve stability of automated tests
-
- Closed
-
-
-
- Closed
-
-
LOG-806
upgrade rancher/kubernetes from 1.6.18/1.10 to 1.6.22|23/1.11 to align with INT-586 71375 29 Oct upgrade
-
- Closed
-
-
-
- Closed
-
-
LOG-924 Kubernetes chart dependencies - make all 105 in 87 files conditional - post yaml for cd
-
- Closed
-
-
-
- Closed
-
-
-
- Closed
-
-
-
- Closed
-
-
-
- Closed
-
-
-
- Closed
-
-
 TSC-101
Dublin kubernetes deployment stability tracking
TSC-101
Dublin kubernetes deployment stability tracking
-
- Closed
-
- is duplicated by
-
LOG-300
CD: OOM framework for continuous E2E deploy validation of tagged commit/merge trigger docker snapshots
-

- Closed
-
- relates to
-
LOG-992
RKE 0.16 / Docker 18.06 for ONAP installation - migrate from Rancher for Dublin - script support
-
- Closed
-
-
LOG-266
F2F: ONAP CI/CD using OOM Kubernetes
-
- Closed
-
-
-
- Closed
-
-
LOG-895
Upgrade Rancher to 1.6.25 to address CVE-2018-1002105 and move to Kubernetes 1.11.5 (server side)
-
- Closed
-
-
-
- Closed
-
-
LOG-300
CD: OOM framework for continuous E2E deploy validation of tagged commit/merge trigger docker snapshots
-
- Closed
-
-
-
- Closed
-
-
-
- Closed
-
-
-
- Closed
-
-
-
- Closed
-
-
-
- Closed
-
-
LOG-296
Provide user friendly deployment profiles for all component subtrees of ONAP
-
- Closed
-
-
-
- Closed
-
-
-
- Closed
-
-
LOG-305
Docker images must merge/build on each commit not daily
-
- Closed
-
-
-
- Closed
-
-
OOM-1568
Define configuration overrides for target deployment environment
-
- Closed
-
-
-
- Closed
-
-
TSC-70
ONAP and OPFNV collaboration - specifically ARM based AWS VMs
-
- Closed
-
-
TSC-75
CVE security governance of deployment undercloud (Docker, Kubernetes, Helm, Rancher) - propose new CLM job
-
- Closed
-
-
VVP-130
DEV mode dev.yaml override for all remaining ReplicaSet counts still above 1
-
- Closed
-
-
-

- Closed
-
- links to
- mentioned in
-
Page Loading...
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-